
| <= Previous | Index | Next => |
Это чрезвычайно хитроумно, чрезвычайно сложно и крайне эффективно, но в то же время грубо, неэкономно и топорно, и чувствуется, что есть лучший способ.
К. Стрэтчи (говоря не о Windows, а о компьютере IBM Stretch в 1962 г.)
Если пытаться создать универсальный интерфейс, в котором были бы учтены те требования, о которых шла речь в предыдущих главах, то выяснится, что для этого нужно радикально изменить нашу обычную практику. Здесь возможно много направлений. Одно из них заключается в том, чтобы посмотреть, что мы можем сделать в условиях существования Интернета и сотен миллионов компьютеров, а также других устройств обработки информации, которые уже существуют или которые только разрабатываются сегодня.
В настоящее время аппаратная конфигурация обычного персонального компьютера является почти универсальной. Если принять точку зрения, что внутри почти всех приложений, использующих общие аппаратные средства, акцент делается на унификацию физических действий, у нас появляется возможность разработать всеобъемлющий и в то же время простой интерфейс.
Набор действий, которыми пользователь влияет на содержание — будь оно текстовым, графическим или мультимедийным, — можно организовать в простую таксономию, с помощью которой мы сможем описать любой интерфейс в некой унифицированной форме. Такая организация позволила бы упростить разработку интерфейсов. Например, внедрение универсального средства «отменить/повторить» (undo/redo) тоже позволяет создавать единообразные интерфейсы, тем самым избавляя от необходимости придумывать средство обработки ошибок специально для каждой программы.
Разные приложения имеют разные наборы команд, и пользователь обычно не может в целом использовать команды приложения А при работе с приложением В или наоборот. Если же сделать команды независимыми от приложений, то тем самым мы сможем устранить модальность, которая изначально им присуща. При такой унификации общее количество команд, которое пользователю придется запоминать, существенно сократится, — главным образом потому, что унификация позволит избавиться от огромного числа повторений команд. Например, в компьютере Canon Cat с помощью всего 20 команд можно было управлять текстовым процессором, электронными таблицами, созданием, сортировкой и обработкой баз данных, вычислениями и т.д. В современных системах аналогичной мощности используется более 100 команд для выполнения того же самого набора задач. Тысячи команд, которые используются в современных средах, можно было бы сократить до сотни. Так как не все команды могут применяться ко всем типам данных, возникнет необходимость применять к объектам преобразователи типов данных, чтобы создать новые объекты, к которым при определенных условиях уже можно будет применить выбранную команду.
Кроме того, может быть снято и другое разделение, которое имеется сегодня между теми средствами, которые содержатся в коммерческих программных продуктах, и теми, которые могут быть созданы самим пользователем. Например, сегодня меню являются объектами операционной системы, которые устанавливаются в каждом приложении. Однако меню представляют собой всего лишь какой-то текст. Почему бы тогда не дать возможность пользователю самому составлять список часто используемых команд, защитить его от случайного изменения, прикрепить наверху экрана и использовать его как обычное системное меню? Для упрощения создания таких меню в интерфейсе можно было бы предусмотреть возможность блокировать и разблокировать какой-то текст, а также возможность его перемещения вместе с другим содержанием или закрепления в каком-то месте на экране. Текст может быть в разных состояниях.
Хотя Eudora и Microsoft Word являются программами, в которых можно изменять меню, тем не менее, для изменения его содержания вы должны использовать только специально предназначенные для этого средства. В данном случае мы как раз и говорим о том, что должна быть возможность создавать меню обычными средствами создания и редактирования текстов. В этом смысле меню можно рассматривать как содержание.
Еще одним шагом к упрощению интерфейса является устранение трудно запоминаемых и неудобных файловых имен, а также системных файловых структур. При наличии хороших механизмов поиска использование имен файлов и файловых структур перестает быть необходимым.
Сущности не должны множиться без необходимости.
Уильям Оккамский
Набор аппаратного оборудования, из которого состоит интерфейс компьютера, стал стандартным — одно или несколько устройств для ввода текста (клавиатура, планшет для письма, устройство распознавания речи), ГУВ и двухмерный цветной дисплей. Эта, в общем неплохая, формула может иметь некоторые различия. Например, сенсорный экран может использоваться одновременно в качестве устройства ввода текста, ГУВ и дисплея. Микрофоны, устройства ввода видеоданных и другие устройства обычно не входят (кроме случаев экспериментирования) в состав обычного человеко-машинного интерфейса. На самом деле мы используем интерфейс для того, чтобы контролировать функционирование этих устройств.
Если вы посмотрите на человека, который работает с каким-нибудь существующим сегодня стандартным компьютерным оборудованием, но не будете видеть, что отображается на экране монитора, и знать, какую задачу оператор выполняет, и, в общем, не сможете предположить, что он делает. Конечно, здесь возможны исключения. Если вы видите, что пользователь пристально смотрит на экран и маниакальным образом вращает ручку джойстика под ритмичные и повторяющиеся звуки, то сможете догадаться, что, скорее всего, он играет в какую-то компьютерную игру. Но, в целом, действия пользователя при использовании одного приложения, например текстового процессора, в большой степени похожи на действия, которые он выполняет при использовании других приложений, например баз данных или электронных таблиц.
Такое однообразие действий пользователя в разных приложениях подсказывает нам, что интерфейсы для различных приложений не так уж и отличаются друг от друга, как вам самим это может показаться при использовании этих приложений. Приложения отличаются друг от друга больше потому, что вы обращаете внимание на содержание того, что выполняется, т.е. на различные изменения смысла каждого действия. В частности, вы не обращаете внимание на физические действия, которые выполняете при работе на компьютере.
Другой аспект, который является общим почти для всех приложений, заключается в том, что при их использовании требуется вводить какой-то текст. (Даже в играх вам иногда приходится вводить собственное имя в случае выигрыша.) Поэтому стоит подумать над тем, чтобы обработка текста — будь это небольшой текст, как, например, цепочка символов в строке поиска, или, наоборот, большой текст, как, например, текст романа — была обеспечена набором удобных и эффективных команд.
И люди, и наше программное обеспечение не являются совершенными. Не все нажатия клавиш, движения пером или речевые действия приводят к отображению именно тех символов, которые нужны. Поэтому в интерфейсе должна быть предусмотрена возможность сразу стирать символы на экране с помощью клавиши Backspace или Delete и применять эти средства и для других форм введенных данных. Для внесения еще больших изменений, как, например, добавление абзаца, требуется предусмотреть возможность выделения и удаления целых областей. В отношении больших участков текста также важно, чтобы пользователь имел возможность переместить курсор в любое место текста, чтобы вставить туда символы. Другими словами, всякий раз, когда вводится текст, пользователь ожидает, что в его распоряжении должны быть многие возможности текстового процессора.
Когда вы вводите текст, вы помещаете его в какой-то документ или поле, как, например, область формы, предназначенная для ввода своего имени. В существующих сегодня системах допустимые функции редактирования различаются в зависимости от поля или типа документа, — для документа текстового процессора это могут быть одни правила редактирования, для электронных таблиц — другие. Правила редактирования могут различаться даже внутри одного документа, который содержит элементы, созданные с помощью других приложений (в разделе 5.7 мы рассмотрим одно из решений этой проблемы).
Два различных, но внешне схожих сегмента программного обеспечения какой-либо системы могут быть для пользователя большим источником ошибок и негативных эмоций. Однако именно такая ситуация наблюдается почти во всех персональных компьютерах. На моем компьютере установлено 11 текстовых редакторов, в каждом из которых имеется свой набор правил редактирования. Возможно даже, что в нем имеются и какие-то другие редакторы, которые я упустил. Таким образом, все это приводит к бесполезной путанице.
Для создания человекоориентированного интерфейса для компьютеров или компьютерных систем (таких, например, как Palm Pilot) важным шагом является обеспечение одинаковых правил для всех случаев, в которых вводится или редактируется текст. Например, в Macintosh или Windows вы не можете при вводе имени файла сделать его орфографическую проверку, поэтому, если вы не уверены в правильности написания слова рандеву (randezvous), которое вы хотите использовать в качестве имени файла27, то вам придется вводить его наугад или открыть текстовый процессор и набрать в нем (или скопировать) это слово, чтобы проверить правильность написания. Могу предположить, что если бы я подал разработчикам программного обеспечения идею о том, чтобы пользователь мог проверять орфографию файловых имен, то они, весьма вероятно, и добавили бы такую возможность, но такое особое добавление, — которое, вероятно, было бы решено в виде какого-нибудь нового элемента в одном из системных меню (скорее всего, меню Правка), — только бы увеличило и без того абсурдную сложность программного обеспечения. Наилучшим решением здесь было бы упрощение на основе уже описанной идеи, заключающейся в том, что одна команда орфографической проверки должна применяться к любому тексту, независимо от того, какую роль он играет в данный момент.
Разработка интерфейсов должна быть основана на идее, что любые объекты, которые выглядят одинаково, одинаковы. Этот принцип может существенно упростить интерфейс с точки зрения как пользователя, так и разработчика и может быть применен не только в отношении текстов. Любой объект в этом случае становится состоятельным. Если пользователь не может по виду объекта на экране определить, что с ним можно и чего нельзя делать, это означает, что ваш интерфейс не удовлетворяет критерию видимости, который мы обсуждали в разделе 3.4. Тем самым вы ставите пользователя в положение, при котором ему необходимо догадываться о том, какие операции допустимы и к каким последствиям они могу привести. Техника создания интерфейсов, при которой пользователю в результате приходится догадываться о возможностях элементов программного обеспечения, является более подходящей для разработки игр, чем прикладных инструментов.
В идеале невозможно достичь того, чтобы по внешнему виду всегда можно было определить функцию. Например, один объект может быть очень похож на какой-то другой. Растровое изображение текста выглядит точно так же, как и сам текст не в графическом формате, однако в сегодняшних системах невозможно применять операции текстового редактирования к растровым изображениям. Эта проблема может быть частично решена, если в системе будет предусмотрена возможность конвертирования объекта в тот формат, в котором данная операция может быть к нему применена (об этом см. далее в разделе 5.8).
Если вы разрабатываете интерфейс, то должны знать палитру всех его возможностей, аналогично тому, как художник имеет на своей палитре набор всех возможных красок. Спектр элементарных действий, которые пользователь может выполнить, довольно ограничен. Все взаимодействие между пользователем и интерфейсом построено на этом наборе элементарных действий. С помощью клавиатуры вы можете стучать по клавишам или же нажимать и удерживать их, выполняя при этом какие-то другие действия. С помощью ГУВ вы можете перемещать курсор в пределах экрана (или экранов) вашей системы и, таким образом, управлять компьютером, регулируя скорость, направление и ускорение движения ГУВ (хотя обычно скорость и ускорение движения ГУВ используются опять же только с целью указания). С помощью кнопки ГУВ вы можете передавать информацию о том, на какое место на экране монитора вы хотите указать. Все эти элементарные действия могут иметь весьма различный смысл в зависимости от того, в каком приложении они применяются.
Сенсорные графические планшеты могут регистрировать угол наклона пера, что связывает с каждой указанной пользователем позицией еще два числовых значения. Эти значения редко используются за исключением тех случаев, когда пользователь занимается рисованием от руки. Музыкальные клавиатуры позволяют ввести в компьютер как скорость, так и силу, с которой клавиша нажимается. Кроме того, существуют такие устройства, как джойстики и устройства ввода трехмерных данных. Тем не менее, в большинстве случаев используется обычная клавиатура и стандартное, двухмерное ГУВ. В этом разделе будут рассмотрены, главным образом, стандартные устройства ввода и вывода данных. Во многих случаях будет понятно, каким образом излагаемые принципы могут быть распространены и на более необычные физические или даже ментальные интерфейсы. Полагаю, что ясная таксономия и перечень элементарный действий, а также выполняемых с их помощью операций, могут быть весьма полезными для обсуждения и разработки интерфейсов.
Элементарные действия, выполняемые пользователем в различных комбинациях, порождают набор элементарных операций, которые применяются к содержанию и используются почти во всех интерфейсах. Перечислим, какие операции могут быть применены к содержанию:
Эти элементарные операции могут и должны быть основой компьютера или самой программы, т.е. они должны являться частью аппаратного или базового программного обеспечения, а не входить в состав множества программных пакетов, и каждая элементарная операция должна всегда вызываться одинаковым образом, независимо от того, к каким объектам они применяются. В основном когнитивные различия между программами заключаются в способах представления выделенного содержания и того, как пользователь может с ним оперировать. В электронных таблицах значения представляются в табличной форме, а применяемая к ним операция может состоять в том, что столбец без итогового значения внизу преобразуется в столбец, внизу которого указывается сумма значений всех его ячеек. В текстовом процессоре текст и иллюстрации представляются в виде страниц, а типичной операцией, применяемой к ним, является изменение начертания текста с обычного на наклонное. В программе обработки веб-страниц страница из текстового процессора может быть преобразована в HTML-формат. В программе обработки фотоизображений фотография с низким контрастом может быть преобразована в фотографию с высоким контрастом.
Большинство операций, выполняемых с содержанием, можно описать с помощью этих элементарных операций. Например, во многих системах имеется возможность сделать запрос о свойствах какого-нибудь объекта. (Если система оснащена двухкнопочным ГУВ, пользователь обычно может выполнить это действие с помощью нажатия на правую кнопку при условии, что курсор наведен на этот объект и система находится в соответствующем состоянии.) Запрос свойств объекта означает, что необходимо получить дальнейшую информацию об элементе или набор связанных с ним опций. Но также его можно рассматривать и как операцию, примененную к одному объекту, чтобы вывести на экран связанный с ним другой объект. С точки зрения пользователя, нет необходимости в том, чтобы операции, выполняемые в операционной системе, отличались от операций, выполняемых в приложениях, и поэтому такого различия не должно быть.
То, что интерфейсы всех приложений основаны на небольшом наборе элементарных операций, подтверждает тот факт, что приложения как таковые не очень отличаются друг от друга с точки зрения интерфейса, независимо от того, насколько они сложны и разнообразны с точки зрения задач, для которых они предназначены. Такое базовое подобие можно использовать для создания мощных компьютерных систем, обладающих беспрецедентной степенью простоты и эффективности.
Для начала нам следует определить несколько методов отбора и выделения содержания, к которому предполагается применить какую-то операцию. Эти методы будут рассмотрены в разделе 5.2.1.
Подсветка (highlighting) означает, что с помощью каких-либо средств отображенному на экране объекту придается заметное отличие. Функция подсветки заключается в том, чтобы пользователь мог, пассивно наблюдая изображение на экране, определить, что некоторый объект получил от системы особый статус. Семантика этого статуса зависит от типа объекта и от команд, которые пользователь может применить к данному объекту. Для зрячих пользователей выделение обычно визуально. В качестве визуальных методов выделения может использоваться обращение яркости, изменение цвета или контраста, подчеркивание, мигание или любое другое периодическое изменение, добавление к объекту статичной или анимированной рамки. В качестве не визуальных методов выделения может использоваться набор разных голосов или изменение интонации.
Когда пользователь наводит курсор на какие-то объекты, они должны быть подсвечены. Типичным объектом в текстах является символ. Подсветка единичного объекта при перемещении курсора без каких-то других действий со стороны пользователя (как, например, нажатие на кнопку мыши) является указанием (indication). С помощью указания пользователь может в любой момент знать, на какие объекты он указывает с точки зрения системы. В очень многих современных системах пользователь должен догадываться о том, что будет выделено или активировано при нажатии на кнопку ГУВ. Если догадка неверна, пользователю придется сделать другую попытку, что приводит к потере времени и сил. Указание может быть особенно полезным, когда объекты, которые пользователь хочет выделить, имеют небольшие размеры или расположены близко друг к другу, или перекрывают друг друга, или их границы неясны. Указание необходимо в тех случаях, когда интерфейс разработан в соответствии с принципом видимости.
Подсвечивание, используемое для указания, не должно быть слишком контрастным или ярким, чтобы движение курсора не вызывало раздражение. В некоторых случаях полезно, чтобы указание объектов не происходило, если скорость перемещения курсора превышает определенное пороговое значение. Следует обратить внимание на то, что чем меньше объект (т.е. чем меньше визуальный угол указанного объекта), тем больший контраст должен использоваться для его указания — однако это вопрос эргономический.
Указание недостаточно используется в современных системах. Активное использование указания в разработке интерфейса позволяет существенно сократить количество щелчков мышью в сравнении с современными интерфейсами. По сути дела, указание часто может заменить клик мышью, и вместо двойного щелчка можно делать только один, как при выборе ссылки в броузере. Допустим, что пользователь хочет убрать неактивное окно с экрана. В каждом окне имеется кнопка Закрыть. Для этого как в операционной системе Windows, так в Macintosh пользователь должен сначала щелкнуть по окну, чтобы сделать его активным, и только потом нажать на кнопку Закрыть. Этот лишний щелчок, который делается для активизации того окна, которое пользователь, на самом деле, хочет закрыть, вызывает особое раздражение. Но если бы окно можно было активизировать всего лишь перемещением к нему курсора, то для закрытия окна одного нажатия на кнопку мыши было бы достаточно. Конечно, если вы разработаете систему, в которой активизация происходит только в определенных местах или при определенных условиях, то тем самым вы создадите модальное противоречие, которое будет только сбивать пользователей с толку. Активизация должна происходить системно. Поскольку такой подход становится более известным, спрос на него со стороны пользователей увеличит его распространение.
Выделение (selecting) — это процесс, с помощью которого пользователь указывает, что один или несколько объектов имеют особый статус, который может быть воспринят системой. Как результат процесса получается выборка (selection). Обычно пользователь делает выборку с целью применения к ней в ближайшем времени команды. В отличие от менее постоянного указания, выделение, обозначающее выборку, является более устойчивым и сохраняется, даже если пользователь отведет курсор в сторону. Пользователь может выделить объект, щелкнув по кнопке ГУВ, указывающего на него. Кроме того, пользователь может сделать выделение расположенных рядом объектов с помощью вырисовывания прямоугольника или другой фигуры, при этом все объекты, которые окажутся в области фигуры, будут выбраны. Другим удобным способом отбора является создание многоугольника или произвольной фигуры. В этом случае все объекты, оказавшиеся внутри фигуры, будут выбраны после того, как пользователь замкнет ее границу. После того как выбор сделан, предыдущая выборка должна стать старой выборкой (old selection). (В большинстве современных систем старая выборка просто-напросто отменяется (deselect).) Этот процесс может быть многократно повторен, поэтому пользователь может создать дополнительно к первой старой выборке вторую старую выборку, третью и т.д. — вплоть до n-й старой выборки. У математика здесь, скорее всего, возникнет желание назвать текущую выборку нулевой старой выборкой. Выделение, с помощью которого обозначается выборка, должно быть более заметным и отличаться от того, которое используется для указания. Выделенные старые выборки также должны хорошо отличаться друг от друга — возможно, с уменьшением визуального контраста для более старых выборок. Для легкого распознавания старых выборок они могут иметь буквенно-цифровые обозначения.
Выборка может включать как отдельный объект на экране, так и геометрическую область, или же быть составной из различных выборок. В большинстве современных интерфейсов пользователь делает составные выборки — в том числе и разрывные — из набора отдельных выборок, для чего необходимо сделать начальную выборку. Затем, как правило, пользователь может нажать клавишу <Shift> и, удерживая ее и находясь, таким образом, в квазирежиме, щелкнуть по другим объектам, чтобы присоединить их к общей выборке или отсоединить их от нее.
Однако этот способ имеет три недостатка. Во-первых, команда для создания составных выборок является невидимой. Во-вторых, при создании большой составной выборки легко допустить ошибку (например, если пользователь случайно отпустит клавишу <Shift> и щелкнет по следующему объекту, вся сложная выборка, которая была создана к этому моменту, будет потеряна). В-третьих, механизм используется как «переключатель»: один и тот же жест служит как для отмены выделения (если объект был уже выделен), так и для установки выделения (если объект был не выделен).
Первая проблема заключается в отсутствии видимости и может быть легко решена с помощью, например, экранной подсказки. Вторая проблема заключается в том, что при составлении выборки имеется большой риск совершения ошибки. Более удобный способ создания сложных выборок состоит в наличии специальной команды, с помощью которой текущая выборка определяется как объединение старого и текущего выделения. Такая команда позволила бы пользователю сосредоточиться на создании выборки, не заботясь о том, что было выбрано до этого. Только после подтверждения текущего выделения она может быть добавлена к составной выборке. Возможность обращения к старым выборкам и обозначения каждой из них особой подсветкой позволяет применять команды с множеством аргументов, как, например, использование двух аргументов для команды взаимозамены двух выборок. Сравните метод перестановки двух участков текста, который вы используете сейчас, с другим методом: создание двух выборок и затем применение команды перестановки.
В большинстве существующих сегодня систем команды Отменить (Undo) и Повторить (Redo) нельзя применить к процессу создания выборок. Это не совсем оправданно, поскольку ошибки при создании выборок случаются довольно часто. Необходимым элементом любого человекоориентированного интерфейса являются универсально применимые команды Отменить и Повторить. Число или уровни допустимой отмены выполненных команд должны ограничиваться только лишь объемом доступной памяти. Команды Отменить и Повторить должны быть всепроникающими и применяться к любой операции, которая логически может быть повторена или отменена. Также эти команды должны быть обратными друг другу (инверсивными) — опять же в той мере, насколько это логически возможно. Это означает, что выполнение команды Повторить после команды Отменить или выполнение команды Отменить после команды Повторить не должно приводить к изменениям в содержании. Очевидно, что эти команды не должны применяться к самим себе. Операторы Отменить и Повторить являются основополагающими, и их функция настолько важна, что в будущих системах для них должна быть предусмотрена специальная клавиша. Команда Повторить должна назначаться следующим образом: Shift↓Undo↓↑↑. На клавише должны быть ясно обозначены два слова: Отменить (Undo) и Повторить (Redo) (рис. 5.1). Такая клавиша могла бы с большей пользой заменить собой вызывающую много проблем клавишу <Caps Lock>.
Что касается третьей проблемы, то в разделе 3.2, посвященном переключателям, я уже говорил, что в челокекоориентированном интерфейсе переключатели вообще не должны использоваться. В данном случае простым решением проблемы могло бы быть использование одной команды или квазирежима для добавления объекта к выборке, а другой команды или квазирежима — для удаления объекта из выборки. При попытке добавить к выборке объект, который там уже имеется, или удалить из выборки объект, которого в ней нет, сама выборка останется неизменной.
Интерфейс обычно имеет одну точку, в которой, как предусматривают разработчики, должен проходить процесс взаимодействия между пользователем и системой — точку фокуса. Например, если вы печатаете слепым методом и набираемый вами текст появляется на экране, то место, где появляется текст, является фокусом и часто совпадает с локусом вашего внимания. Если вы не владеете методом слепого набора, то ваш локус внимания будет перемещаться между клавиатурой и дисплеем. В интерфейсах в каждый момент обычно имеется только один курсор. Его позиция определяется с помощью ГУВ, клавиш управления курсором или команд (например, Найти (Find)).
Локус внимания всегда находится на каком-то физическом, ментальном или отображаемом объекте. То же самое можно сказать и о системном фокусе. Например, в существующих текстовых процессорах при перемещении курсора внутрь документа (действие, которое само по себе не должно быть необходимым) он может быть расположен между двумя буквами, и, таким образом, может показаться, что никакой объект не является фокусом системы. На самом деле в фокусе находятся две буквы — та, которая слева и может быть удалена командой Delete28, и та, которая справа и где появится следующая введенная буква.
Когда процессом взаимодействия управляет человек, в фокусе обычно находится текущая выборка. Если же система отвечает на действие пользователя или внешней системы, в фокусе обычно находится результат действия.
Я как писатель-фантаст уверен, что этот чертов робот должен говорить на человеческом языке, а не наоборот.
Спайдер Робинсон
Некоторые команды (как, например, Отменить) не обязательно могут применяться к выборкам. Другие команды действуют только по отношению к текущей выборке — как, например, команда, которая удаляет текущую выборку. Некоторые из этих команд вводятся с клавиатуры. Однако число клавиш на клавиатуре меньше, чем количество возможных команд. Каждая дополнительная клавиша-модификатор (как, например, <Shift>, <Alt>, <Command>, <Control> или <Option>) позволяет удвоить число клавиатурных команд. Полная клавиатура, в которой любая комбинация клавиш может быть воспринята компьютером, допускает астрономическое число сочетаний клавиш. Например, программное обеспечение, в котором предусмотрено использование любых трехклавишных дваждыквазимодальных сочетаний на 110-клавишной клавиатуре, позволяет передать более одного миллиона команд с помощью только одного жеста. Однако широкое использование клавиш-модификаторов, особенно в сочетаниях клавиш, очень часто приводит к появлению чрезвычайно сложных комбинаций, в которых можно просто «сломать пальцы». Кроме того, комбинации редко бывают запоминаемыми или понятными. (Знаете ли вы, какое действие выполняет на вашем компьютере сочетание <Control>+<Shift>+<Option>+<\>?) Запомнить различные сочетания клавиш не просто. Такое запоминание является недопустимым требованием к памяти пользователя. Кроме того, такие команды нарушают критерий видимости, если только в системе каким-то образом не отображается то, какой результат будет получен при применении той или иной команды. Конечно, если в отдельных случаях какой-то из этих жестов не может быть выполнен или если жест имеет разные значения в разные моменты, это означает модальность системы по отношению к данному жесту, что приводит к проблемам, которые обсуждались в главе 3.
Если разделить систему на приложения таким образом, что данная команда может многократно использоваться, но с разными значениями в разных приложениях, появляется возможность увеличить количество команд, которые пользователь может вызвать для заданного множества сочетаний клавиш. Однако использование команд в приложениях, в которых для них устанавливаются разные значения, приводит к модальным ошибкам. Кроме того, различающийся смысл жеста создает ненужные трудности для его запоминания. Частично эта трудность облегчается с помощью меню. Тем не менее, пользователю все равно приходится запоминать, где находится та или иная команда. (Возможно, пользователю даже придется сначала вспомнить, в каком именно приложении используется необходимая ему команда, особенно если используется несколько приложений с подобными функциями.) Процесс просматривания меню иногда становится привычным, но иногда он оказывается утомительным, особенно если искомая команда находится в каком-то из подменю и если способ организации меню, который показался разработчику очевидным, не является таковым для пользователя.
Для назначения команд требуется такой метод, который был бы таким же быстрым и физически простым, как нажатие на пару клавиш, и с помощью которого было бы проще и быстрее найти необходимую команду, чем с помощью системы меню. Нежелательно повторять двойной метод, который используется в большинстве известных графических пользовательских интерфейсах и включает в себя как систему меню, так и набор непонятных горячих клавиш. Например, нет ничего запоминаемого в сочетании
Command↓ v↓ ↑↑
которое используется для вставки, кроме того, что клавиша v расположена рядом с клавишей c, используемой в сочетании
Command↓ c↓ ↑↑
которое запоминается несколько лучше, поскольку с может напоминать слова «вырезать» (cut) или «скопировать» (copy).
Другой метод позволяет решить многие из этих проблем. Предположим, что на клавиатуре есть клавиша <Вычислить> (Calculate). При нажатии на эту клавишу текущая выборка рассматривается как арифметическое выражение и вычисляется. Далее я буду использовать подчеркивание, чтобы показать выборку. Допустим, что текст является следующим:
Я хочу купить 3+4 рубашек
При нажатии на клавишу <Вычислить> он будет преобразован в следующий текст:
Я хочу купить 7 рубашек
До нажатия на клавишу <Вычислить> 3+4 было обычным текстом, Он ничем не отличался от остального текста, за исключением того, что он был выделен. Пять символов (включая пробелы), из которых состояла выборка, можно было переместить или удалить, или же к ним могла быть применена любая другая обычная команда текстового процессора. Но в данном случае была использована операция Вычислить. Пользователю не потребовалось открывать окно калькулятора или вызывать специальное приложение.
Теперь рассмотрим случай, когда на клавиатуре нет клавиши <Вычислить>. (Хотя специальная клавиша для вычисления математических выражений — это пока только ценная идея, но она, несомненно, была бы более полезной, чем те клавиши, которые уже существуют, как, например, <F9>.) То, что нам необходимо — это более общий механизм для команд.
Перед обсуждением такого механизма рассмотрим требования, которым должен отвечать новый метод вызова команд:
Проиллюстрируем один общий метод примером. (Этот несколько тривиальный арифметический пример используется только для того, чтобы продемонстрировать данный метод. Более эффективные способы применения этого метода будут рассмотрены далее.) Предположим, что имеется следующий текст:
Я хочу купить 3+4 рубашек вычислить
Выделим сумму 3+4, и затем выделим слово вычислить, при этом сумма станет старой выборкой.
В другом методе, который предоставляет пользователю всю мощь командной строки, при нажатии на клавишу <Command> вызывается выбранная команда. Если для выполнения команды требуется аргумент, то в его качестве используется старая выборка. В данном методе сама команда удаляется, а результат вычисления становится левой выборкой.
Я хочу купить 7 рубашек
Суть заключается в том, что команды не должны ограничиваться только меню, но могут быть частью вашего текста, или же, если это уместно, команда может быть представлена графическим объектом, а не словом или набором слов. Важно также и то, что в этом случае пользователь может назначать команды самым простым способом — всего лишь набирая их с клавиатуры или рисуя их. Такой способ не противоречит методу, при котором команда выбирается из уже имеющегося списка.
Преимуществом меню является то, что список команд, из которых оно состоит, является видимым. Тем не менее, вместо того чтобы выбирать команду из меню, пользователь может с такой же легкостью выбирать команду из небольшого документа, в котором содержится список всех команд. Такой документ может быть составлен как разработчиками, так и самим пользователем. Кроме того, в этом документе может быть не только список команд, но и, например, описания команд и даже заметки, сделанные пользователем. Такой документ, служащий в качестве меню, может использоваться как обычный текстовый документ, а не как нечто, что может быть изменено только программистами или только с помощью специальных средств настройки.
Такой подход имеет ряд преимуществ. Например, онлайновые руководства автоматически содержат примеры использования команд, которые в нем описываются. В современных системах команды, имеющиеся в меню, могут как иметь, так и не иметь своего клавиатурного аналога. Однако при таком подходе каждая команда, описанная в меню последовательностью символов, имеет свой клавиатурный эквивалент. Это обеспечивается не благодаря стараниям разработчиков, а по самой природе такой системы. Как команда из меню, так и клавиатурный эквивалент имеют одинаковое написание. И большинство пользователей будут чаще использовать именно клавиатурный эквивалент. Другим преимуществом этого подхода является то, что вы можете составить меню только из тех команд, которые вы используете, просто набрав их в список с помощью текстового процессора. Конечно, если вы постоянно изменяете список, а не просто, скажем, добавляете к нему новые команды, то теряется преимущество их привычного расположения.
Аналогично тому, как гиперссылки в тексте часто выделяются визуальными методами, например изменением цвета (обычно на синий) и подчеркиванием, команды также могут обозначаться какими-то особыми способами (например, красным цветом или обратным курсивом). При таком выделении пользователь сможет указывать на имя команды (или на какую-то из букв ее имени) и затем вызывать ее нажатием на клавишу <Command>. В этом случае выделение команды для ее вызова перестает быть необходимым.
Если для команд не использовать особый шрифт или цвет, то придется предусматривать другие правила для обозначения того, что какое-то слово или последовательность слов следует рассматривать как единую команду. Разумнее было бы избежать использования каких-то из существующих сегодня условностей, которые используются для группировки отдельных слов в одну единицу, разделенную пробелами или другими символами. Например, если бы у нас была команда, которую мы бы хотели назвать «преобразовать изображение в формат JPEG», то по существующим правилам нам пришлось бы написать ее в виде преобразовать.изображение.в.формат.JРЕG, <преобразовать изображение в формат JPEG> или преобразовать_изображение_в_формат_JРЕG. Такие способы написания являются слишком «компьютерными», неудобными и унылыми, особенно для тех, кто только знакомится с компьютерами. Синтаксис, который мы выбираем для написания команд, не должен исключать пробелы или символы новой строки. Любые ограничения, накладываемые на набор допустимых символов, используемых для набора команд, в будущем приведут к проблемам. Более того, любые подобные ограничения пользователю придется учитывать при назначении команде имени. Следует также иметь в виду и другой принцип, заключающийся в том, что использование обычаев, которые не совпадают с традициями обычной речи, приводит к возникновению непонимания между пользователем и компьютером. Следует сделать так, чтобы машина подстраивалась под нас, а не подстраивать обычаи естественной речи под то, что проще решить с точки зрения программирования.
Еще одно взаимодействие ввода с клавиатуры и создания выборки вызывает проблемы в сегодняшних интерфейсах. В человекоориентированном интерфейсе ввод с клавиатуры не замещает выделенный текст и не отменяет выделение текущей выборки. Это отличается от распространенного правила, в соответствии с которым ввод символов замещает содержимое текущей выборки, что время от времени приводит к проблемам в тех случаях, когда новый материал неожиданным для пользователя образом удаляет текст, который он не собирался удалять. Идея, что при вводе символов они должны замещать выборку, стала использоваться для того, чтобы сэкономить на одном нажатии клавиши — в большинстве редакторов, чтобы заместить текстовый блок, вы можете просто выделить его и начать ввод. Без этого правила пользователю придется сначала выделить некоторый текст, затем нажать <Backspace> или <Delete> и потом вводить новый текст. В способе, который используется сегодня, экономится только лишь нажатие на клавишу <Backspace>, при этом при первом нажатии текст исчезает и замещается текстом, который вводится далее. Это происходит независимо от того, находился ли замещаемый текст на экране или нет и (обычно) состоял ли он из нескольких символов или трех четвертей вашего документа. Таким образом, вне локуса вашего внимания вы можете удалить текст в 40 страниц. Если вы вовремя заметите это, то, наверное, сможете отменить действие. Но если же вы не заметите удаление, и если ничего не подскажет вам, что текст был удален, вам может не повезти. Человекоориентированный интерфейс никогда не подвергает работу пользователя риску. Экономия одного нажатия на клавишу куплена за слишком большую цену. Случайная потеря хотя бы одного символа может означать потерю части телефонного номера или адреса электронной почты, которая не может быть восстановлена из оставшейся части. Удаление текста должно проходить явным образом по желанию пользователя и не быть побочным эффектом другого действия.
Понятие локуса внимания позволяет точно определить, что мы определяем как побочный эффект. Побочный эффект — это следствие применения команды, при котором изменяется содержание или события, которые не находятся в локусе вашего внимания. В только что рассмотренном случае в локусе вашего внимания находится текст, который вставляется, а побочным эффектом является удаление. Устранение побочных эффектов должно быть одной из целей для разработчика человекоориентированпого интерфейса.
Другой возможностью текстовых процессоров, которая часто считается полезной, является перетаскивание выделенного текста из одного места в другое. Однако при этом у пользователя нет возможности создать другую выборку, которая пересекалась бы с текущей, или создать под выборку текущей выборки. Если вы попытаетесь сделать какую-нибудь из этих выборок, система воспримет это действие как попытку переместить текущую выборку. Это означает, что сначала вам следует щелкнуть в каком-то месте вне выборки, чтобы снять ее выделение. Таким образом, жесту перетаскивания были даны два разных значения, а именно: выделение и перетаскивание выборки. Это может препятствовать формированию привычки. Ошибки возникают в результате того, что, хотя символы выборки находятся в локусе вашего внимания, текущее состояние выборки не находится в локусе вашего внимания, несмотря на то, что оно визуально выделено. Во время моих наблюдений я видел, как некоторые пользователи могли случайно перетащить выборку, хотя собирались создать новую выборку.
Другая проблема возникает при перетаскивании текста (она также может возникать и в графических программах): иногда случается так, что как только вы начинаете перетаскивать выборку, выясняется, что место, куда вы хотите перенести ее, не видно на экране. В этом случае приходится возвращать выборку обратно или ставить ее в другое место и применять метод вырезания и вставки. Принцип монотонности предполагает, что предпочтительным является наличие только одного метода. В некоторых системах при перетаскивании выборки к нижнему или верхнему краю экрана автоматически начинается его прокрутка, но она происходит слишком медленно, если место назначения находится на расстоянии нескольких страниц. Кроме того, прокрутка может происходит и слишком быстро, что не позволяет остановиться или даже заметить необходимое место.
Если бы не маркетинг, я бы не стал оснащать интерфейс возможностью перетаскивания текста, по крайней мере, в том виде, в каком эта опция сейчас используется на персональных компьютерах. В этом случае меньшее число ошибок и проблем было бы хорошей компенсацией для тех пользователей, которые привыкли к возможности перетаскивать текст. Желательно, чтобы для выделения и для перетаскивания использовались отдельные квазирежимы, поскольку тогда не будет возникать «когнитивная путаница» между этими опциями. Например, ГУВ может быть снабжено кнопкой для создания выборок, а также специальным устройством (например, встроенной сбоку кнопкой), с помощью которой можно было бы сжимать ГУВ (при этом для того, чтобы было понятно, что действие произошло, важно наличие тактильной обратной связи, например в виде щелчка кнопки), что означало бы, что вы забрали выборку. В этом случае между этими функциями не возникало бы никакой путаницы (или она была бы минимальной). После нескольких секунд объяснений и одной-двух попыток использования такого устройства уже было бы понятно, как им пользоваться. Более простой метод для разделения функций выделения и перетаскивания заключается в том, чтобы использовать другую кнопку мыши для перетаскивания или же использовать квазирежим (например, удерживание в нажатом положении специальной, ясно обозначенной кнопки во время использования основной кнопки мыши). (См. более подробно в приложении А.)
Функцию перетаскивания, которой может быть оснащен ГУВ, можно также использовать вместо прокручивания. Вы можете захватывать какую-то часть документа и с помощью этого устройства перемещать ее: верх или вниз — в узких документах, и во всех направлениях — в широких документах. Когда курсор перетаскивания (который в некоторых из сегодня существующих системах разумно отображается в виде руки) достигает границы экрана, прокручивание продолжается в выбранном направлении до тех пор, пока пользователь не отпустит устройство перетаскивания или не вернет курсор обратно внутрь окна. Метод прокручивания с помощью полос прокрутки может приводить к путанице. В частности, при нажатии на кнопку со стрелкой вниз содержимое экрана прокручивает вверх. Если же использовать стрелки, повернутые в другую сторону, это создаст только еще большую путаницу. Кроме того, кнопки со стрелками на полосе прокрутки имеют небольшие размеры и поэтому требуют больше времени при использовании, а, как хорошо показывает анализ по закону Фитса, возможность захватывать элементы в любой части документа является намного более быстрым способом.
Вышеописанный пример со специальной функцией захватывания, которой может быть оснащена мышь, показывает, что при разработке интерфейсов программного обеспечения часто могут возникать идеи по улучшению аппаратного оборудования, так же как те или иные характеристики аппаратного строения могут приводить к улучшению программного обеспечения. Необходимо сказать, что всегда лучше разрабатывать аппаратное и программное обеспечение вместе, несмотря на то, что такая возможность редко случается. Попытки «подставить» чистый программный интерфейс в аппаратное оборудование, которое было разработано для другого интерфейса, редко могут дать удовлетворительные результаты. Тем не менее, в большинстве случаев это именно то, что мы должны сделать.
Элементы человекоориентированного интерфейса должны быть доступными для начинающего пользователя и эффективными для опытного пользователя, причем переход от одного к другому не должен требовать переучивания. Хороший интерфейс должен давать одну ментальную модель, которая подходит для обоих классов пользователей, с учетом, конечно, того факта, что по отношению к одним частям системы мы можем быть опытными пользователями, а по отношению к другим — начинающими. В предыдущем разделе было предложено, чтобы клавиша, выполняющая некоторый текст как команду, могла быть применена к выделенному тексту независимо от его происхождения. В результате выполняется определенная команда, при условии, что выделенный текст является именем этой команды, — в противном же случае никакого действия следовать не должно. Хорошо, если бы для ввода команд можно было использовать квазирежим с помощью удерживания клавиши <Command>. Однако это удобство в существенной мере зависело бы от эргономичности клавиши <Command>. В целом, такая возможность улучшила бы использование систем с командной строкой, которые многим нравятся за скорость и удобство работы, но, в то же время, многими ненавидятся за трудность в изучении. Улучшения здесь два: вы можете подавать команды в любом месте и в любое время, а т.к. команды аналогичны представленным в меню, то можно легко переходить от меню к непосредственной подаче команд и обратно.
Ввод команд требует специального места, а также времени на то, чтобы его найти, поэтому удобнее, чтобы пользователь мог ввести команду в любом месте, где находится курсор, и в тот момент, когда это требуется. После выполнения команды введенное имя команды должно быть удалено с тем, чтобы имена команд не оказались разбросанными по всему содержанию. С другой стороны, если вы выполняете команду из списка, то удаление имени команды нежелательно, поскольку список, по сути дела, является меню. Создание такого меню не должно требовать ничего, кроме как напечатать список команд, выделить его и затем применить к нему команду (например, Создать Меню (Make Menu)), чтобы назначить командам особый стиль, который обычно используется для написания команд, а также чтобы заблокировать этот список во избежание его случайного изменения.
Приведем некоторые другие команды, изменяющие состояние текста. С помощью команды Заблокировать (Lock) можно просто запирать текст или другое содержание. Заблокированное содержание можно просматривать, выделять и копировать, но нельзя изменять или перемещать. Обратная команда — Разблокировать (Unlock) — может быть применена к выделенному содержанию для его разблокировки при условии, что оно было заблокировано (в противном случае команда не дает никакого результата, т.е. она не должна быть переключателем). С помощью другой команды — Заблокировать с паролем (Lock with Password) — можно заблокировать старую выборку, используя текущую выборку в качестве пароля. Эта команда также имеет обратный аналог (Разблокировать по паролю (Unlock with Password)). Возможность заблокировать какое-то содержание может быть довольно полезной. Например, она может использоваться для создания стандартных форм для заполнения. Неизменные элементы формы могут быть заблокированы, в том числе и по паролю, при этом простое блокирование позволит предотвратить случайные изменения, а блокирование по паролю — несанкционированные изменения. Если бы электронная инструкция по использованию некоторой компьютерной системы входила в набор текстов, с которыми компьютер изначально поставлялся, — что в общем является неплохой идеей, — то такое руководство, вероятно, блокировалось бы производителем по паролю еще на заводе.
Команды Экранная блокировка (Screen Lock) и Экранная разблокировка (Screen Unlock) позволяют заблокировать и разблокировать позиции объектов, выделенных на экране. С помощью этих команд пользователь может создавать меню, которые будут сохранять свое место на экране, в то время как другие объекты перемещаются под ними. Можно даже связывать позицию меню с днем недели (насколько такая возможность является полезной — это уже другой вопрос). Чтобы использовать эту команду, вы размещаете объект в требуемой позиции на экране, выделяете его и применяете команду Экранная блокировка. Также должна быть версия этой команды с использованием пароля для тех случаев, когда нежелательно, чтобы пользователь мог изменить позицию того или иного меню.
Другой полезной командой является регулировка прозрачности выборки. В некоторых ситуациях, таких как, например, отображение сообщений об ошибках, полезно сформировать выборку достаточно прозрачной, чтобы лежащий под ней материал можно было видеть и продолжать с ним работать (рис. 5.2). Аналогичным образом с помощью другой команды можно было бы определять, скрывает ли данный объект другой объект либо скрывается им, либо просматривается через него. Прозрачное окно сообщения может исчезать медленно, а не внезапно, давая пользователю время заметить его. Также необходимо, чтобы в некотором документе сохранялись все сообщения для последующего обзора.

Для удаления прозрачного диалогового окна не требуется нажатие какой-либо клавиши, так как вы можете продолжить работу через него. Такое окно не создает режимов и является высокоэффективным (эффективность составляет 1). Как и любой другой метод, эта идея имеет свои ограничения и может быть использована чрезмерно. Поток ненужных сообщений все равно отвлекает внимание, даже если пользователь может продолжить работу во время того, как они исчезают. В соответствии с принципом видимости, должно быть предусмотрено визуальное отличие для текста, который является заблокированным, экранно заблокированным, заблокированным по паролю и т.д.
Принцип человекоориентированного интерфейса заключается в том, что система сама должна быть построена из тех же самых элементов, что знакомы вам по повседневному использованию этой системы. Такой подход позволяет создавать более понятные продукты.
Люди скорее готовы страдать до последней возможности, чем защищать свои права через уничтожение тех форм правительства, к которым они привыкли.
Томас Джефферсон, из Декларации независимости Соединенных Штатов Америки
Для многих пользователей максимально возможная в Macintosh длина имени файла в 31 символ была просто счастьем в сравнении с ужасным ограничением в 8 символов в более ранних системах. Тем не менее, даже такая модификация являлась всего лишь смирительной рубашкой большего размера. За исключением некоторых реальных ограничений, налагаемых аппаратным оборудованием, интерфейс не должен иметь ограничений, связанных с длиной. Интерфейс должен использовать распределение динамической памяти, ссылки, хеширование или любые другие методы, но никогда не должен ставить для пользователя ограничений, таких как «вы можете использовать не более 255 категорий» или «объем абзаца не должен быть более 32,000 символов»29.
Чем является имя файла? С точки зрения пользователя, это «ручка», за которую файл можно взять. По своему опыту мы знаем, что имена файлов работают не так, как этого стоило бы ожидать, — они мешают, когда нужно что-то сохранить, и бывают бесполезными, когда нужно что-то найти. Если говорить более конкретно, файловые имена становятся назойливыми, когда вы собираетесь что-то сохранить, так как вам приходится останавливаться в середине самого процесса сохранения, чтобы придумать имя для файла30. Создание имен — это трудное занятие. Требуется на месте, за пару мгновений выдумать уникальное, запоминающееся имя, которое, к тому же, должно отвечать правилам, принятым в данной файловой системе. Кроме того, в этот момент в локусе вашего внимания находится не проблема создания имени файла, а вопрос сохранения вашей работы. Файловые имена приводят к неудобствам и при поиске файлов. Имя, которое вы придумали, может быть не особенно запоминающимся, и поэтому вы, вероятно, можете забыть его через несколько недель (или даже раньше). Я, например, редко когда могу вспомнить имя файла, если только я не пользовался им совсем недавно, и даже простое просматривание списка файлов вызывает смятение. Ну, скажите, что может содержаться в файле с именем «notes ybn 32»? Когда я придумывал его, оно казалось таким умным и запоминающимся. Кроме того, многие файлы очень похожи друг на друга. Сколько разных, оригинальных и запоминающихся имен вы можете выдумать для писем к своему бухгалтеру по поводу оплаты налогов за прошлый год? Их, конечно, можно организовать по дате, но многие ли из нас способны помнить, что, например, письмо о списании служебного грузовика было написано 14 августа?
Необходимость давать имена файлам увеличивает ментальную нагрузку на пользователя. Назначение имени не делает ничего, кроме добавления к самому файлу еще нескольких символов. И вам приходится запоминать этот файл только лишь по тому кусочку символов и больше ни по чему другому. Я считаю это одним из главных бедствий, которым страдают современные компьютерные системы. Этот метод используется также и во многих других информационных средствах.
Между именем файла и самим файлом не должно быть различия. Человеческий мозг способен более эффективным образом использовать быструю, полнотекстовую поисковую систему, поэтому любое слово или фраза из файла может служить ключом к нему. (Более того, желательно, чтобы по запросу «письмо о стрекозе» выполнялся поиск чего-либо в форме письма, а также не только слова стрекоза, но и связанных с ним терминов и выражений в случаях, если упоминались научные названия этого вида (например, Odonata). Если такие письма обнаружены не были, поиск должен продолжиться среди документов, не являющихся письмами, и так далее, расширяясь до сетевых ресурсов и Интернета.) Вы не можете помнить содержание документа по его имени «Письмо Джиму от 21/12/92», но вы можете помнить, что когда-то вы писали Джиму по поводу одной голубой Edsel, которая однажды пролетала мимо вас. Поиск по слову Edsel найдет только один или два элемента во всей вашей системе, если только вы не интересуетесь именно видом Edsel — в этом случае вы, вероятно, выбрали бы другую схему поиска. Неограниченное по длине имя файла является самим файлом. Содержание текстового файла и есть его самое лучшее имя.
Графические и звуковые файлы зачастую тоже требуют своих имен. В разделе 6.2 будет рассмотрен подход, в котором обходятся те трудности, которые накладывают традиционные файловые структуры на нетекстовые файлы. Если не говорить о нетекстовых файлах, наличие быстрой полнотекстовой системы поиска позволяет отказаться от использования целого вида бесполезных элементов — файловых имен. Вместе с отказом от имен файлов также отпадает необходимость в механизмах их обработки (например, каталогах), правилах их создания и синтаксических ограничениях при создании. С устранением файловых имен исчезает большая ментальная нагрузка на пользователя, а также значительная часть внутреннего программного обеспечения — того, что в настоящее время пользователям приходится изучать, а программистам разрабатывать.
Наилучшей моделью интерфейса для полнотекстовой системы поиска является интерактивная, в которой вы можете видеть каждый найденный элемент в его контексте. В таком интерфейсе вы сразу оказываетесь там, где вам необходимо, как только вы это увидели. В некоторых системах делаются копии найденных элементов в том ряду, в котором они содержатся (Drori, 1998). Однако в сравнении с первым методом поиска этот метод не является эффективным, поскольку вам придется затем выполнить еще вторую операцию по получению самого элемента (например, вам придется дополнительно щелкнуть по копии необходимого документа).
Для тех пользователей, которые хотят иметь систему, напоминающую обычную файловую структуру, может быть предусмотрена специальная команда по созданию «информационного документа» или дополнительной страницы в конце каждого документа, когда документ выбран и такая команда применена. Информационный документ или дополнительная страница может содержать информацию о дате и времени создания или изменения документа, историю редакций, размер и другую полезную информацию. Программное обеспечение, предназначенное для выполнения такой команды, должно получать и хранить необходимую информацию невидимым для пользователя образом.
Разработчики могут поставлять разные средства в зависимости от потребностей пользователя. Для пользователей, предпочитающих старые методы, можно предусмотреть утилиты для создания документов, которые могли бы выглядеть и действовать так же, как и те неудобные каталоги, которыми мы сейчас пользуемся.
Другой тип организации, который легче изучить и использовать, чем обычные файловые системы, происходит из естественной иерархичности, присущей многим естественным языкам. В них слова разделяются пробелами, предложения (или последовательности слов) разделяются одним из небольшого числа разделителей (в английском языке в число этих разделителей входит точка, вопросительный и восклицательный знаки) и последующим пробелом. Абзацы (или последовательности предложений) разделяются, по крайней мере, одним знаком возврата каретки. Символ раздела или разрыва страниц служит для отделения глав или других уровней организации текста.
В последовательной системе разрыв страницы должен быть символом и, в отличие от большинства современных систем, он должен вести себя как любые другие символы с точки зрения их вставки, удаления и поиска. Как и символ возврата каретки, символы разрыва страниц могут быть скрытыми символами, обозначающими фиксированную длину физической страницы, но они не должны быть частью содержания31.
Имеет смысл не ограничиваться этими иерархическими уровнями, как это делается во многих современных системах. Документы являются последовательностями страниц, разделенных символами этого документа, каждый из которых может быть набран, найден или удален так же, как и любой другой символ. Также могут быть разделители и более высокого уровня, как, например, символ папки и тома или даже разделитель секции и библиотеки. Тем не менее, число уровней определяется объемом данных. Набор из двух последовательных символов документа является хорошим разделителем для наборов документов. Если требуются другие уровни организации, то три или четыре последовательных символа документа можно использовать в качестве разделителей. Вместо клавиш <Папка> (Folder), <Том> (Volume) и <Библиотека> (Library), которые будут использоваться редко, можно предусмотреть клавишу <Документ> (Document), которую можно нажимать многократно, вплоть до четырех раз соответственно. Такое решение позволит избежать резкого увеличения количества клавиш на клавиатуре. Важно, чтобы все символы разделителей имели специальную клавишу, иначе они не будут работать как все другие набираемые символы. То есть пользователь не должен нажимать на какую-то клавишу (например, <Return>) и потом применять команду Вставить разрыв страницы. Для этого он должен использовать только специальный символ страницы.
Если разнообразные символы разделения работают так же, как и все другие символы, исчезает необходимость в обучении пользователей тому, как с ними управляться. Если пользователь все же настаивает на использовании явных имен документов, он может ставить такие имена сразу после символа документа. Для того чтобы найти документ с именем «Собаки Азии», поиск должен будет производиться по фразе «Собаки Азии», перед которой стоит символ документа. При таком поиске будут игнорироваться все случаи использования последовательности «Собаки Азии», кроме тех, которые используются в качестве имени документа. Для получения каталога может использоваться команда, которая сможет собрать документы, включающие искомую подстроку и предваряющиеся символом документа, а также другими символами, вплоть до и включая ближайший символ конца абзаца или разделитель более высокого уровня.
Отказ от использования иерархической файловой структуры не означает отказ от структурирования сохраняемой информации. Ничто не мешает вам создавать оглавления и указатели или размещать все ваши письма к дяде Альберту и тете Агате на соответствующих страницах. Ничто не мешает вам создавать сразу перед письмами титульную страницу (как отдельный документ) «Письма к дяде Альберту и тете Агате». В этом случае вы, в сущности, создадите файловое имя, но оно не потребует использования специальных механизмов в программном обеспечении. По желанию, если вы действительно любите файловые имена и иерархии, вы можете создать свою собственную иерархическую файловую структуру. Однако тогда, структура будет частью вашего содержания, а не интерфейса.32 Поэтому вместо специального механизма поиска файлов вы сможете использовать обычные средства поиска. Перед группой файлов вы можете поместить в виде документа название папки. Также перед группой папок вы можете поместить название тома. (В этом случае за символом тома будет следовать название тома, чтобы избежать совпадений с другими такими названиями, не являющимися именами тома.) Отсутствие встроенной файловой организации не мешает созданию файла, предназначенного для какой-либо цели, но, в то же время, понятного вам, т.к. он создан именно вами. Тем не менее, поскольку система при этом никак не изменяется, другой пользователь может искать что-либо в ваших данных и фактически проигнорировать вашу структуру и рассматривать ее как сплошной, неструктурированный файл.
Преимуществом организации произвольной файловой структуры является то, что такая структура не устанавливается разработчиками системы, у которых могут быть совсем другие идеи, отличные от ваших. В этом случае вам не приходится создавать ментальную модель того, что разработчики пытались сделать. У многих пользователей формируются неправильные модели того, как та или иная система работает. Ментальные модели трудно изменяются и поэтому они могут долгое время создавать трудности для таких пользователей (Norman, 1988).
Сказанное не является теорией. Отказ от использования в компьютерах SwyftWare и Canon Cat файловых имен, директорий, а также от механизмов, с помощью которых с ними производятся манипуляции, оказался одним из самых удачных решений. Пользователи, привыкшие к использованию обычных компьютерных систем, признавали, что им было трудно перейти к использованию систем, основанных на принципе организации информации по содержанию. Но когда такой переход происходил, обычные методы вскоре казались им неудобными. А пользователи, которые начинали знакомиться с компьютерной техникой с компьютера Canon Cat, не испытывали радости от необходимости изучать более сложные методы использования обычных файловых систем, когда они переходили на PC или Macintosh.
В сравнении с обычными графическими пользовательскими интерфейсами методы, описываемые в этой книге, могут показаться сложными. Но кажущаяся сложность возникает только лишь из-за того, что новый подход еще не знаком, а также из-за того, что мы привыкли к тому множеству действий, которое мы должны выполнить, и к тем проблемам, которые возникают при использовании существующих сегодня систем. Конечно, новая система потребует от пользователя усилий на изучение. Но если вы сравните успехи начинающих пользователей, работающих с разными системами, или сравните эффективность работы опытных пользователей, преимущества более простой системы станут очевидными.
Представьте, что у вас есть n документов, которые вы должны скопировать на внешний носитель — пусть это будет жесткий диск. Для этого, используя, например, операционную систему Macintosh, вы должны будете перетащить пиктограмму каждого документа на пиктограмму диска. Новая парадигма, на первый взгляд, делает операцию более сложной. Вам нужно найти начало и конец каждого документа, выбрать документ, переместить курсор к нужному месту на диске и затем переместить каждый документ.
Вспомните, что в обычном графическом пользовательском интерфейсе вы всегда начинаете с открытия некоторого общего приложения. Ваш первый шаг — это добраться до рабочего стола. Вы должны помнить, какие пиктограммы соответствуют нужным документам, и вам (или кому-то другому) всегда приходится выполнять действия по назначению имен этим документам. Вы также должны помнить, в какой папке эти документы находятся. Поэтому кажущаяся простота достигается только после того, как выполнен значительный объем работы, и пользователь разделался с большим количеством обременительных ментальных требований. Более эффективным методом является изобретение под названием LEAP. Предположим, что, как и в случае для обычного графического интерфейса, курсор находится в одном из документов, которые вы хотите переместить. С помощью LEAP пользователь может выбрать документ шестью нажатиями клавиш, причем не глядя на экран и не держа в голове имя документа. Нажатие 6 клавиш отнимает меньше времени, чем перетаскивание пиктограммы.
Функция LEAP работает следующим образом: имеется две клавиши <LEAP>, находящиеся под большими пальцами. <LEAP-Up> производит поиск вперед от позиции курсора, a <LEAP-Down> — назад. При нажатии на клавишу <LEAP> включается квазирежим, после чего все, что вы ввели, воспринимается как шаблон поиска. Для выборки документа вы должны нажать <LEAP-Up> и ввести символ документа (LEAP-Up↓ Doc↓ ↑↑). Мы перемещаемся к началу документа. Затем мы нажимаем <LEAP-Down> и вводим символ документа (поиск в этом случае найдет символ документа в конце документа). Одновременное нажатие на обе клавиши <LEAP> позволяет выделить весь текст. (Вероятно, удобнее всего это делать с помощью больших пальцев, которые редко используются при работе с клавиатурой. См. рис. 2.1 с изображением обычной клавиатуры, снабженной клавишами <LEAP>. Альтернативным вариантом является клавиша <Выбрать> (Select).) Для того чтобы сделать эту функцию видимой, рядом с клавишами <LEAP> необходимо поместить какое-то обозначение. Например, можно использовать надпись: «Для создания выделения нажмите одновременно на обе клавиши LEAP». Обратите внимание, что пользователю не требуется смотреть на экран при выборе документа. Когда документ выбран, нажатием клавиши <LEAP> курсор перескакивает на тот объект, куда нам необходимо вставить текст, после чего дается команда Копировать (Copy). При таком выделении документ включает свои разделители. Таким образом, если документ перемещается, он сохраняет в себе свою сущность как документ, поскольку эти разделители перемещаются вместе с ним.
Та же самая техника, которая использовалась для копирования документов (или другой выборки любой длины, начиная от единственного символа и заканчивая набором документов или даже всем содержанием системы (!)) из одного места в другое, может быть использована и для перемещения выборки. Разница состоит только в том, что подается команда Переместить (Move) вместо команды Копировать (Copy). В функциональном отношении этот процесс является не более сложным, чем аналогичные процессы в обычных пользовательских графических интерфейсах. Зачастую он оказывается более быстрым, а число методов, понятий и структур, которые должен знать пользователь, оказывается меньшим.
Сравним перемещение нескольких выборок из разных документов на диск с помощью клавиши <LEAP> с выполнением этой же задачи в обычном пользовательском графическом интерфейсе. В первом случае метод будет аналогичным тому, который применялся для перемещения документов на диск. Объекты, предназначенные для выборки, сначала находятся (при этом необходимости их открывать нет), потом они выбираются, как это было описано выше (за исключением того, что в начале и в конце выборки используются символы не документа, а текста), и затем они копируются в нужное место. В обычном пользовательском графическом интерфейсе пользователь должен сначала открыть документ, в который будет производиться копирование (возможно, это потребует использования команды Создать (New) из меню Файл (File)), потом найти документ, который содержит нужную выборку, открыть этот документ, найти выборку внутри документа, выделить ее, применить команду Копировать (Copy), сделать активным документ назначения, вставить выборку, активировать рабочий стол, найти следующий документ, содержащий нужную выборку, повторить всю процедуру до тех пор, пока все выборки не будут — вставлены в документ назначения. После этого вы должны сохранить результат на диске, используя специальное диалоговое окно.
Даже если бы уровень сложности выполнения задач был одинаковым для обоих подходов, концептуальная простота методов, описанных в этой книге, делала бы их более предпочтительными. В большинстве же случаев объем необходимой работы также оказывается намного меньшим, чем при использовании обычных интерфейсов.
Маленький шаг большого человечества.
Нейл Армстронг (1969)
Прежде чем продолжить рассмотрение функции LEAP, имеет смысл рассмотреть несколько более подробно вопрос использования интерфейсов для поиска. Строкой (string) называется последовательность33 символов. Обычные английские слова и предложения являются примерами строк. При поиске по строке (string search) происходит просмотр (обычно длинной) последовательности, называемой текстом, с целью обнаружения (обычно короткой) последовательности, указанной пользователем и называемой шаблоном (pattern). Каждый случай совпадения между подстрокой текста и заданной комбинацией называется объектом поиска (target). Например, при попытке найти в большом письме место, где вы писали о кошке по кличке «маленькая Татсу», наиболее подходящим объектом поиска будет маленькая Татсу, а еще более короткая строка Татсу будет хорошим шаблоном. Совпадение может быть полным, может зависеть от регистра символов или от других параметров (например, соответствие может быть по рифме). Наиболее распространенный критерий поиска, по которому легко искать, заключается в том, что строчные буквы в задаваемой комбинации соответствуют как строчным, так и прописным буквам в тексте, тогда как прописные буквы в задаваемой комбинации соответствуют только прописным буквам в тексте. Обычно поиск начинается от текущей позиции курсора и осуществляется вперед. В большинстве систем с помощью модальных пользовательских установок можно произвести поиск в обратном направлении (рис. 5.3).
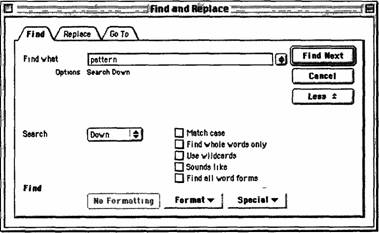
Интерфейсы к средствам поиска обычно строятся на основе двух подходов. Наиболее распространенным является поиск с разделителями (delimited search), который встречается в большинстве текстовых процессоров. В типичном поиске с разделителями пользователь включает режим, в котором любой введенный текст рассматривается как шаблон для поиска. Обычно для этого используется диалоговое окно, снабженное полем для ввода символов. После вызова диалогового окна пользователь вводит комбинацию символов и разделитель, в качестве которого обычно используется некий символ, запрещенный к отображению в шаблоне (например, Return). В большинстве диалоговых окон пользователь также может ограничить шаблон нажатием на кнопку OK, Search, Find или Find Next с помощью ГУВ. Когда объект поиска обнаружен, он выбирается, а курсор располагается сразу в конце выборки.
Этот традиционный метод является довольно злосчастным для пользователя, хотя большинство компьютерщиков настолько привыкли к этому, что уже не замечают никакого неудобства. Например, пользователь может ввести последовательность для поиска с опечаткой, но заметить ее слишком поздно, т.к. он уже нажал по привычке клавишу <Return>. Поэтому ему придется сидеть и ждать, пока закончится поиск, который, как уже заранее известно, не даст результата. Большинство систем поиска являются непрерываемыми, и это является серьезной ошибкой разработчиков. Из-за того, что компьютер ждет, пока пользователь закончит ввод шаблона, по которому начнется поиск, поиск с разделителями часто вынуждает пользователя ждать без необходимости.
Менее распространенным методом является пошаговый поиск (incremental search), известный пример которого можно увидеть в текстовом редакторе EMACS, работающем под операционной системой UNIX (Stallman, 1993). В большинстве случаев использования пошагового поиска, так же как и при поиске с разделителями, пользователь должен сначала вызвать диалоговое окно, в котором имеется поле для ввода шаблона поиска. Когда пользователь вводит первый символ шаблона, система использует этот символ как полный шаблон и сразу же начинает поиск первого экземпляра этого символа в выбранном направлении. Если экземпляр этого первого символа обнаруживается до того, как введен следующий символ шаблона, то он выбирается, а курсор помещается сразу в конце выборки. Если же следующий символ шаблона вводится до того, как экземпляр обнаруживается, то этот символ добавляется к шаблону и поиск продолжается теперь уже в отношении экземпляра расширенного шаблона. Процесс повторяется по мере добавления символов к шаблону поиска.
При использовании клавиши <Backspace> или <Delete> для удаления символов из шаблона пошагового поиска поиск возвращается к предыдущему экземпляру, найденному по тому шаблону, который был до добавления к нему следующего символа. Пользователь может затем добавить символы к шаблону, чтобы продолжить поиск без сброса результатов уже выполненного поиска по неполному шаблону. Многие системы поиска не имеют этой полезной характеристики.
Пошаговый поиск имеет ряд других преимуществ в сравнении с поиском с разделителями. Пошаговый поиск требует меньше времени. Поиск начинается, как только первый символ шаблона введен. Система не ожидает того момента, когда шаблон будет введен полностью. При использовании поиска с разделителями компьютер ждет, пока пользователь полностью введет шаблон и обозначит его разделителем, после чего уже пользователь ждет, пока компьютер производит поиск. При использовании поиска с разделителями пользователь должен сначала предположить, по какому шаблону компьютер сможет отличить нужный объект от других подобных объектов, тогда как при использовании пошагового поиска пользователь сразу же может определить, что шаблон оказался достаточным, чтобы выявить нужный объект, потому что он уже появился на экране. Таким образом, как только пользователь видит, что нужная точка найдена, он может прекратить введение шаблона. Если же он введет слишком много символов, т.е. скорость ввода будет больше, чем скорость поиска, шаблон все равно будет введен, и курсор установится приблизительно в том месте, которое предполагается. Если пользователь ошибается при вводе шаблона в систему поиска с разделителями, для исправления ошибки он должен ждать до тех пор, пока поиск по неверному шаблону не завершится, — в лучшем случае пользователь может воспользоваться механизмом для остановки поиска, если такой предусмотрен. В большом тексте поиск может занимать значительный период времени. В хорошо разработанном пошаговом поиске пользователь может удалить неверно введенный символ в любое время и возвратиться к последнему найденному экземпляру. Поскольку использование клавиши Backspace для исправления ошибки может быть привычным, процесс исправления проходит довольно быстро, и поиск останавливается сразу же. Чтобы возобновить поиск, пользователь может ввести правильный символ.
Еще одним преимуществом пошагового поиска является то, что в нем имеется постоянная обратная связь во время введения символов шаблона, т.е. результаты поиска видны сразу. При использовании поиска с разделителями пользователь не знает, насколько введенный им шаблон является подходящим или даже насколько правильно он был набран, до тех пор пока ввод не закончен и попытка поиска не начата. С точки зрения построения интерфейса, пошаговый поиск имеет так много преимуществ, а поиск с разделителями — так мало, что, на мой взгляд, использование поиска с разделителями редко когда может быть предпочтительным.34 Несмотря на то что почти все разработчики и пользователи признают, что пошаговый поиск более предпочтителен, почти все инструменты по разработке интерфейсов позволяют создавать средства поиска с разделителями и затрудняют или даже делают невозможным создание средства пошагового поиска. Примерами таких инструментов являются JavaScript и Visual Basic.
Пошаговый ввод шаблона поиска делает возможным изменять шаблон интерактивно прямо во время процесса поиска, а значит, позволяет пользователю оптимизировать поиск по получаемой обратной связи. Даже построение булевой модели поиска делается более эффективным, если результаты поиска отображаются по мере того, как пользователь уточняет шаблон. Найденный экземпляр должен появляться посередине экрана, а не наверху или внизу, так, чтобы материал до и после экземпляра был виден, таким образом, найденный экземпляр всегда отображается в своем контексте. Найденный экземпляр также должен всегда отображаться в одном и том же месте относительно экрана или окна, чтобы пользователь быстро выучил, где искать результаты. В компьютере Canon Cat найденный экземпляр всегда появлялся по вертикальному центру экрана. Он не должен отображаться на каком-то из краев экрана; таким образом, материал вокруг экземпляра всегда был виден.
Если в тексте не содержится экземпляра шаблона, поиск оказывается неудачным. Во многих системах в этом случае поиск прекращается и не может использоваться до тех пор, пока не нажата специальная клавиша (обычно <Enter> или <Return>) или кнопка на экране. На экране появляется модальное сообщение, в котором говорится, что вы должны сделать необходимый поклон, прежде чем вам будет позволено продолжить пользование компьютером. В многоэкранных системах или в случаях, когда экран визуально перегружен, такое сообщение может совсем не попасть в локус вашего внимания, и вы можете совсем его не заметить. В результате вам может показаться, что компьютер не отвечает на нажатие клавиш, как будто бы он завис. При использовании же пошагового поиска вы без всякой специальной подсказки сможете заметить, что поиск не удался, потому что курсор в этом случае сразу же возвращается в начальную позицию, и дополнительные нажатия не дают никакого результата. Здесь же может быть полезным короткий звуковой сигнал или мигание на экране, особенно если поиск длился дольше периода действия кратковременной памяти (скажем, дольше 10 секунд), и поэтому пользователь забыл, как выглядел дисплей до начала поиска. Звуковой сигнал еще полезен для пользователей с ухудшенной зрительной способностью.
Другим большим недостатком поиска с разделителями является то, что разделитель, используемый для обозначения конца шаблона, не может быть отображен. Во многих случаях и другие разделители тоже не могут отображаться. Я просмотрел четыре популярных текстовых процессора. В одном из них использование Return вообще не допускалось. Во втором текстовом процессоре для того, чтобы вставить Return в шаблон поиска, пользователь должен набрать ↑r. В третьем текстовом процессоре в этих целях использовалась последовательность \\. В четвертом — Return можно было вставить в шаблон поиска с помощью специального диалогового окна с выпадающим меню, содержащим разные разделители (рис. 5.4). Однако было бы легче просто использовать клавишу <Return>. В конце концов, именно таким образом вы вставляете этот разделитель в текст. Почему же при создании шаблона поиска должен использоваться другой метод? Основной принцип состоит в следующем: одна и та же последовательность символов должна набираться одинаковым образом. Пользователь не должен в одном случае применять один метод, а в другом — другой. Иными словами, в отношении специальных символов не должно применяться ничего специального35.
Хотя пошаговый поиск лучше, чем поиск с разделителями, вариант пошагового поиска, который используется в EMACS, может быть все же улучшен. Например, курсор должен возникать не на последнем символе объекта поиска, а на первом. В общем, вы вряд ли можете управлять тем, каким будет последний символ в шаблоне поиска, поскольку вы вводите только те символы, которых достаточно для поиска нужного объекта. Поэтому вы не знаете точно, где окажется курсор после того, как поиск будет произведен. Если же курсор всегда будет устанавливаться на первом символе шаблона, вы можете знать, как отобразится объект поиска. Кроме того, это может быть полезным для быстрого перемещения курсора внутри текста, поскольку в локусе вашего внимания находится символ, на который вы хотите переместить курсор. Придумать шаблон, в котором этот символ является последним, намного труднее, чем просто ввести требуемый символ и последующие за ним другие символы.
В обычных пользовательских графических интерфейсах как пошаговый поиск, так и поиск с разделителями запускается модально, с помощью диалогового окна, тогда как использование клавиши <LEAP> является безмодальным. Идею использования для поиска квазирежима можно дополнить применением специальной кнопки на микрофоне (или ГУВ), удерживаемой для включения квазирежима, в котором вводимые слова, рисунки или рукописный текст могут включаться в шаблон поиска. Другие методы ввода имеют аналогичные средства для создания квазирежима поиска (Raskin и Winter, 1991).
Скорость пошагового поиска может быть увеличена с помощью некоторых приемов. Например, при вводе первого символа искомой строки компьютер сразу приступает к поиску первого экземпляра этого символа в тексте, после чего найденный экземпляр подсвечивается и переносится вместе со своим контекстом в окно экрана. Обычно этот процесс проходит быстро, поскольку в тексте имеется много потенциальных экземпляров и какой-то из них, с большой вероятностью, оказывается поблизости. Пока пользователь вводит следующий символ, поиск может продолжиться в отношении второго экземпляра первого символа и последующего возможного символа в порядке уменьшения частоты использования. Программа может сохранять ссылки на каждый из обнаруженных экземпляров. Как результат, при вводе второго символа компьютер может быть готов отобразить обнаруженный объект, создавая эффект мгновенного поиска.
Поиск строк также может быть ускорен и такими методами, как алгоритм Бойера-Муура (Moore и Boyer, 1977), в котором время поиска уменьшается по мере увеличения длины последовательности. Если пользователь возвращается в шаблоне поиска на одну позицию назад, сохранение ссылки на последнее обнаруженное место (причем для каждого символа последовательности) сделает возвращение чрезвычайно быстрым. Индексирование всех запоминающих устройств может сократить время поиска в локальных системах и сетях до миллисекунд. Скорость взаимодействия через глобальные сети или Интернет также зависит от применяемых методов индексирования. Пошаговый поиск в различных вариантах использовался в таких коммерческих продуктах, как IDE компании Borland, факсовая программа компании Global Village, компьютеры Canon Cat и SwyftWare.
Пошаговый поиск является одним из примеров использования общего принципа разработки человекоориентированных интерфейсов, который заключается в следующем: программа должна взаимодействовать с пользователем на основе наименьшей значимой единицы ввода. Взаимодействие с данными, вводимыми с помощью клавиатуры, должно быть познаковым, а не построчным. Взаимодействие с данными, вводимыми с помощью голосовых устройств, должно быть пословным, а для некоторых приложений даже может быть поморфемным и т.д.
Взаимодействие посредством последовательного ввода строки текста, т.е. строки, отделенной знаком Return, — это пережиток времен телетайпа, который должен быть передан в музеи вместе с оборудованием того времени36. Сегодня мы можем и должны иметь возможность пользоваться интерфейсами, способными реагировать на каждый вводимый символ во всех случаях, когда такая реакция может улучшить качество взаимодействия. Как и всегда, разработчики должны быть внимательны — например, посимвольное взаимодействие не должно приводить к выдаче сообщений об орфографических ошибках в середине набора слова, что может усложнить работу пользователя, владеющего слепым методом набора.
В маленьких текстах, для которых поиск строк был изначально придуман, он обычно проходил от текущей позиции курсора до конца текста. В текстах большего размера в случае, если до конца документа искомый объект так и не был обнаружен, обычно удобнее продолжить поиск с начала документа до позиции курсора, если пользователь забыл, что искомый объект находится выше. Неопубликованное тестирование, проведенное в компании Information Appliance, показало, что если поиск производится быстро, то цикличный поиск оказывается особенно удобным. «Быстрый» означает здесь, что между запуском поиска и его успешным либо неуспешным окончанием не остается времени на действия пользователя. Как правило, это время составляет порядка 250 мс. Во многих системах пользователь может выбрать, каким образом будет проходить поиск — либо циклично (по кругу), либо с остановкой в конце документа. Это порождает типичную проблему модальности. Если установлен нецикличный поиск, и пользователь не знает об этом, сообщение «строка не обнаружена» может привести к неверному пониманию, что в тексте нет экземпляров по запрошенному шаблону поиска. Часто я наблюдал, что в этом случае пользователи несколько раз запускали поиск повторно, т.к. ясно помнили, что видели такой экземпляр в тексте, и не понимали, почему поиск заканчивается безрезультатно. Может пройти несколько секунд или даже минут, прежде чем пользователь догадается, в чем состоит проблема, или же так и останется в недоумении. Если необходимо иметь разные виды поиска, можно избежать использования режимов, предусмотрев для каждого вида поиска соответствующую команду или экранную кнопку для запуска.
Во многих случаях модальности можно избежать с помощью набора кнопок для запуска каждого вида поиска. Такой набор может быть предусмотрен вместо окна установки параметров поиска, снабженного одной-единственной кнопкой запуска поиска по заданным условиям. Такой подход позволяет не только устранить модальность, но и сократить число нажатий. Кроме того, в локусе внимания пользователя в этом случае находится задача, которую он хочет выполнить, а не настройки для ее выполнения. На рис. 5.5 показано типичное диалоговое окно с настройками и кнопкой запуска, которое используется в Microsoft Word. Из рисунка видно, что с диалоговыми окнами этого типа связана и другая проблема: должны ли кнопки переключателя всегда находиться в указанном положении при открытии окна? Должны ли они быть в положении, в котором пользователь оставил их при последнем использовании? Или же они должны быть в некотором положении, установленном пользователем по умолчанию?

Все три варианта являются ошибочными. Если пользователь всегда обновляет оглавление полностью, то при первом варианте ему придется делать каждый раз по два щелчка мышью (или один щелчок и одно нажатие на кнопку <Return>). Если переключатель остается в том положении, в котором окно использовалось последний раз, пользователь не сможет пользоваться этим окном привычным образом, поскольку каждый раз ему придется останавливаться и проверять, в каком положении переключатель находится. Если же переключатель может устанавливаться пользователем в положение по умолчанию (см. раздел 3.2.2), то тем самым включается режим.
Диалоговое окно, изображенное на рис. 5.6, позволяет решить сразу все эти проблемы. Кроме того, по закону Фитса кнопки большого размера имеют преимущество по сравнению с набором переключателей. Если такое окно сделать прозрачным, то можно также отказаться от использования кнопки <Cancel> (см. раздел 5.2.3). В этом случае используемые две кнопки не должны быть прозрачными, чтобы пользователь мог видеть, что они являются активными.
Диалоговые окна для поиска с разделителями обычно снабжены устройством для сохранения текущего шаблона сразу после обнаружения последнего экземпляра. Такое устройство можно назвать «искать еще» или «найти далее». В некоторых вариантах оно запускается с помощью той же кнопки, которая использовалась для начального поиска. Если поиск является пошаговым, то команда для повторного поиска того же объекта является необходимой, поскольку в этом варианте нет никакой команды для запуска начального поиска. Применять для повторного поиска клавишу включения квазирежима <Search> не желательно, т.к. пользователь может нажать эту клавишу, а затем передумать и отпустить ее. В этом случае будет начат поиск, который пользователь не хотел запускать. В результате пользователь может потерять место в тексте, в котором он находился. Хотя использование системы глобального отката может исправить ситуацию, все же лучше вообще не создавать этой проблемы. Специальный метод для выполнения повторного поиска будет рассмотрен в разделе 5.6.
В больших по размеру текстах поиск может осуществляться по кругу (циклично) не только в локальном документе, но и далее, в автоматически расширяющихся областях вплоть до всего Интернета.37 После того как поиск был выполнен по всему локальному документу, он может быть продолжен в отношении последующих документов папки, а затем перейти на начало первого документа папки и продолжиться до текущего, уже просмотренного документа. После циклического поиска внутри папки рассматривается следующая локальная область поиска и т.д. Если во время пошагового поиска, выполняемого таким образом, пользователь поймет, что процесс поиска слишком расширился, он может остановить его, убедившись, что в ближних областях искомого экземпляра нет. Текущую область поиска определить обычно легко, т.к. пользователь может видеть результаты поиска в своих контекстах, а не просто список файлов, как это делается во многих современных поисковых системах.
В общем случае пользователи будут применять более эффективные стратегии поиска, чем просто полагаться на такой метод автоматически расширяющегося поиска. Например, если вы ищете какой-то документ в текущей папке, то, скорее всего, вы станете искать символы документов, чтобы быстро просмотреть начало или заголовок каждого документа. Если нужный документ обнаружен, запускается пошаговый поиск в отношении целевого объекта. Таким образом, обеспечивается порядок, по которому поиск производится в первую очередь в выбранном документе, что позволяет применять более короткий шаблон на меньшей площади поиска. Если же вы не знаете, в каком документе искомый объект находится, или если вы не хотите искать с начала документа, вы можете применить сплошной поиск, который в любом случае обнаружит искомый объект.
Цель как поиска с ограничителями, так и пошагового поиска строки обычно заключается в том, чтобы обнаружить в тексте некоторую строку и выделить ее. Пользователи стараются использовать как можно более короткие последовательности в шаблонах поиска, т.к. длинные последовательности трудно набирать, и в большинстве систем они должны быть набраны с точностью до каждого символа, чтобы соответствовать целевому объекту. Поэтому поиск строки обычно не применяется для выделения даже средних по размеру целевых объектов, длина которых больше, чем 10-15 символов, не говоря уже о действительно больших блоках текста. Поиск строки применяется для того, чтобы помочь пользователю обнаружить место, где расположена искомая выборка, после чего пользователь может применить уже другой метод для обозначения этой выборки (например, использовать ГУВ для перемещения курсора от одного конца выборки до другого). Однако, если края выборки нельзя видеть одновременно, следует использовать другой метод. Он состоит из следующих шагов: (1) обозначение одного края выборки с помощью той техники, которая используется в данной системе; (2) сделать видимым другой край выборки с помощью полос прокрутки; (3) обозначить другой край выборки. В большинстве систем обозначение второго края выборки позволяет выделить всю выборку.
Более эффективный подход заключается в том, чтобы создать такой механизм поиска, который позволили бы размещать курсор на конкретном символе. Два таких размещения курсора можно использовать для обозначения первого и последнего символа выборки. Таким образом, все множество механизмов, обычно используемых для поиска краев выборки (а именно: перемещение курсора, прокрутка, различные механизмы поиска страниц, поиска по шаблону и т.д.) и их обозначения заменяются одним механизмом, который используется два раза, что упрощает процесс изучения, использования и формирования привычек, а также упрощает внедрение.
Рассмотрим теперь графическую форму курсоров. В настоящее время наиболее распространенной формой текстовых курсоров является курсор, который помещается между символами, как это показано на рис. 5.7. Одной из проблем стандартного текстового курсора является то, что пользователи пытаются поместить его точно между символами, целясь на небольшой горизонтальный объект, который по размеру меньше, чем требуемый, что в соответствии с законом Фитса приводит к временным затратам. Кроме того, во время тестирований, проведенных в компании Information Appliance, мы с удивлением обнаружили, что эта распространенная форма курсора создает интересную когнитивную проблему, состоящую в том, что пользователь должен располагать курсор по-разному, в зависимости от того, какое действие он собирается совершить далее. В частности, чтобы удалить существующий символ с помощью клавиши <Backspace>, требуется разместить курсор справа от символа (в английском или любом другом языке, который читается слева направо). Чтобы вставить какой-то символ рядом с существующим символом, необходимо поместить курсор слева от существующего символа (в этом случае существующий символ сдвинется вправо). Наше удивление было связано с тем, что использование стандартного курсора хорошо знакомо каждому пользователю, и поэтому никто не мог подумать, что курсор можно было бы рассматривать как потенциальный источник проблем.38 Любой, кто пользовался курсором, знает, что разобраться с тем, как им пользоваться, несложно. Тем не менее, у начинающих пользователей компьютеров может возникнуть некоторая путаница и ошибки при первых попытках его использования. Путаница усугубляется еще и тем, что пользователи не видят локусы действия применяемых команд.

Введение режима, при котором удаление происходит в направлении, обратном обычному, не решает проблемы. Такой метод, называемый правосторонним удалением (forward erase), позволяет всегда размещать курсор слева от символа, к которому будет применено действие. Однако в этом случае вы будете иногда неожиданно для себя удалять в неправильном направлении, т.к. текущее направление удаления не находится в локусе вашего внимания. Если требуется наличие двух направлений удаления, желательно использовать для этого две разные клавиши или же ввести режим для противоположного направления удаления.
Использование курсора, который визуально показывает как (1) область вставки, так и (2) символ или символы, которые могут быть удалены клавишей <Backspace>, может быть ценным улучшением интерфейсов, ориентированных на работу с текстами. Вторая форма подсветки может быть аналогична той, которая используется для подсветки выборок. Один из способов достижения этого показан на рис. 5.8.
Перемещение курсора к объекту с помощью ГУВ является многократным процессом, в котором пользователь сначала визуально фиксирует целевой объект и затем перемещает курсор к этому объекту. Если пользователь не помнит, где находится курсор, ему также придется визуально искать его местонахождение. После этого он опять ищет целевой объект и т.д. до тех пор, пока объект и курсор не оказываются рядом в одном поле зрения широтой приблизительно 5°. Другими словами, для перемещения курсора с помощью ГУВ пользователь должен выполнить несколько процессов, требующих времени. Тем не менее, ГУВ необходимо для указания на графические объекты или при работе в полностью графической среде.
Неповоротливость ГУВ при работе с текстами усугубляется в случаях, когда возникает необходимость указать на объект, находящийся за пределами страницы. В этих случаях использование только ГУВ вынуждает пользователя использовать полосы прокрутки, переключатели страниц и другие механизмы, чтобы перейти к тому содержанию, на которое нужно указать. Каждый из этих методов требует изучения, и многие из них работают довольно медленно.
Функция LEAP дает пользователю когнитивное преимущество, которое избавляет его от необходимости выбирать между разными методами в зависимости от расстояния до объекта. (Alzofon и др., 1987 г.). Наличие клавиши <LEAP> и ГУВ означает, что имеется два основных способа перемещения курсора. Однако пользователь выбирает тот или иной метод в зависимости от содержания объекта, а не от расстояния между курсором и этим объектом. Обычно содержание уже находится в локусе вашего внимания, поэтому когнитивный выбор между клавишей <LEAP> и ГУВ сделать сравнительно просто.
Использование функции LEAP может быть особенно полезным в системах, управляемых голосом, а также для пользователей с двигательными нарушениями или повторными стрессовыми поражениями, для которых важно минимизировать работу с клавиатурой. Специальная кнопка (например, установленная на микрофоне) может служить для установки квазирежима LEAP. Объектом для функции LEAP всегда является некоторый символ в тексте, и этот символ (независимо от того, смотрит ли пользователь на него или думает о нем) обычно находится в локусе внимания пользователя во время того, как он применяет функцию LEAP. В отличие от использования ГУВ, в этом случае пользователь не должен визуально искать целевой объект, чтобы переместить к нему курсор. Это свойство функции LEAP настолько выражено, что ею могут пользоваться даже слепые пользователи, что было установлено в ходе тестов, проведенных в больнице Ведомства по делам ветеранов в Пало Альто (результаты не опубликованы).
Еще более важным является то, что эта функция может использоваться в системе, построенной на ее основе, так широко, что вскоре оно становится для пользователя автоматичным. В структуре этой функции нет ничего, что могло бы препятствовать формированию ценных автоматичных навыков (привычек) или что могло бы привести к проблемам после того, как такие привычки сформировались. Функция LEAP должна работать быстро, всегда обнаруживая следующий экземпляр текущего шаблона поиска за время, не превышающее время реакции пользователя, чтобы не давать ему возможности и времени выполнить какое-то действие. Необходимая скорость может быть достигнута с помощью методов, рассмотренных в разделе 5.4.
Для сравнения ГУВ и функции LEAP по временным затратам можно использовать метод GOMS-анализа скорости печати. При условии, что руки пользователя изначально находятся на клавиатуре, использование ГУВ для указания на какую-то букву в тексте требует выполнения следующих операций: H P K. С учетом правила размещения операторов M получаем H M P K, или 0.4+1.35+1.1+0.2=3.05 с. Время, необходимое на использование функции LEAP, зависит от количества символов, которые следует ввести, чтобы перейти к требуемому целевому объекту. Тестирование показало, что среднее число символов, используемых при применении функции LEAP, составило около 3.5 для тех пользователей, которые были протестированы в первую неделю использования компьютера Canon Cat. Для перемещения курсора к некоторому целевому объекту требуется выполнить следующие операции: нажать на клавишу <LEAP>, после чего набрать 3.5 символа. Таким образом, применение функции LEAP в среднем состоит из 4.5 символов. Добавление, в соответствии с правилами, оператора М дает в результате 1.35+(4.5*0.2)=2.25 с.
В другом эксперименте по хронометрированию, в котором участвовали опытные пользователи, сравнивалась мышь с функцией LEAP. Задача состояла в том, чтобы переместить курсор между двумя случайно выбранными символами, отображенными на экране размером 25 строк по 80 символов. Отсчет времени не начинался до тех пор, пока пользователь не начинал двигать мышью, или до тех пор, пока он не нажимал на клавишу <LEAP>. Среднее время составило приблизительно 3.5 с для мыши и 1.5 с для клавиши <LEAP>. Увеличение значения по сравнению с расчетным, вероятно, связано с небольшими размерами целевых объектов (в качестве которых использовались отдельные символы), что было обусловлено законом Фитса. Неожиданно малые значения для клавиши <LEAP>, вероятно, могут объясняться небольшими размерами текста, в котором возможный шаблон поиска в среднем мог состоять приблизительно из 2 символов. Участникам эксперимента было дано неограниченное время на планирование своих действий перед использованием мыши или клавиши <LEAP>. Таким образом, во многих случаях пользователь может быстрее завершить передвижение курсора с помощью клавиши <LEAP>, чем переместить свои руки с клавиатуры к мыши.
5.6. Позиция курсора и клавиша <LEAP>
Объектом функции клавиши <LEAP> является отдельный символ. С какой стороны символа должен появляться курсор: справа или слева? Размещение курсора слева от символа правильно только в том случае, если вы собираетесь сделать в этом месте вставку. Тогда как размещение курсора справа от символа правильно при условии, что вы собираетесь удалить этот символ. По-видимому, компьютер должен знать о вашем намерении перед тем, как правильно разместить курсор.
Для случая со вставкой рассмотрим старый курсор в виде прямоугольника вокруг буквы или в виде подчеркивания. При использовании клавиши <LEAP> для перехода к какой-то букве курсор должен располагаться на самой букве. (Курсор не мешает чтению буквы; рис. 5.9.) Тогда пользователь может точно сделать в этом месте вставку или удаление. Прямоугольный курсор позволяет более точно, чем стандартный, межсимвольный курсор, показать место, где произойдет вставка или удаление.

Такой вариант порождает другую проблему. Предположим, что имеется слово tongs. Курсор установлен на букве o. Вы вводите букву h. Получается thongs. Куда должен переместиться курсор? Здесь опять же нужно знать намерение пользователя. Если курсор находится на букве h, то неясно: эта буква является местом вставки или удаления? Удалением должно быть действие, противоположное вставке, — так, чтобы нажатие на клавишу <Backspace> привело к удалению буквы h и возвращению к слову tongs. Но если вы введете другую букву, скажем r, такое нажатие должно сместить букву o к букве h, образуя в результате слово throngs. При использовании надсимвольного курсора, наверное, тоже должны быть предусмотрены средства предварительного определения направления его действия.
Проблема может быть решена следующим образом. Когда вы передвигаете курсор, он должен помещаться на отдельный символ. При вводе или удалении курсор должен разделяться на две части, связанные с двумя прилегающими символами, как это показано на рис. 5.9. Первый символ обозначен удаляющей частью курсора, а второй обозначен снизу указателем вставки. Фокус отчасти заключается в том, что используется курсор из двух частей. Он сделан таким образом, что когда его части объединяются (как они должны это делать после нажатия клавиши <LEAP> или перемещения курсора каким-то другим способом), пользователю графически ясно, что они располагаются на одном символе независимо друг от друга. Все это может показаться сложным, когда описывается словами, но на самом деле для начинающего пользователя научиться пользоваться курсором LEAP проще, чем обычным курсором, изображенным на рис. 5.7. Все, что нужно знать начинающему пользователю — это то, как выглядят маркеры для выделения и вставки, и что клавишей <Delete> удаляется выделенное, а вводимые символы появляются рядом с маркером вставки.
Символы располагаются скорее последовательно, чем смежно, т.к. хотя два последовательных символа обычно и могут быть смежными, они не являются таковыми, если первый из них находится в конце строки. Для языков, которые читаются слева направо, курсор удаления обычно располагается справа от вставляемого символа, а для языков, которые читаются справа налево, — порядок обратный. Для вертикально-ориентированных языков курсор вставки размещался бы под курсором удаления, и для двумерной печати (boustrophedonic scripts) в каждой строке они бы менялись местами.
Восприятие целевых объектов становится проще при использовании ГУВ с курсором из двух частей, поскольку объекты, или символы, больше по размеру, чем пробелы между ними, и поэтому активные области легче обнаружить. (Активная область для курсора PARC распространяется приблизительно до середины каждого символа по обе стороны от пробела между ними. Однако визуально они никак не разделяются, отчего целевой объект кажется меньше по размеру. На практике многие пользователи стараются поместить курсор между символами, тем самым вызывая ограничение закона Фитса, связанное с небольшими размерами целевых объектов.)
Как мы уже говорили, начинающие пользователи иногда испытывают трудности в понимании того, как работает стандартный межсимвольный курсор. Этот переходный процесс связан с интерфейсным элементом, настолько знакомым каждому пользователю, что редко (если вообще когда-то) у кого-нибудь возникает мысль подвергнуть его сомнению. С курсором из двух частей, который при переходе на какой-то символ складывается, упомянутая неясность в том, на какой символ курсор указывает, исчезает и таким образом снимает всю проблему.
В некоторых случаях может быть полезным ограничить действие функции LEAP. Ограничение поиска может быть выполнено с помощью: (1) выделения области поиска; (2) выделения команды или текущей выборки (как это описано в разделе 5.2.1), ограничивающей последующий переход (с помощью клавиши <LEAP>) к этой области, которая становится старой выборкой; (3) использования клавиши <LEAP>. Однако ограничение функции LEAP не должно выполняться путем введения режима. Отсутствие возможности определить, включен режим или нет, делает использование функции LEAP чрезвычайно неудобным — пользователь больше не сможет легко находить необходимые ему объекты. Компания Canon использовала в компьютере Canon Cat механизм, названный «Local Leap» (локальный прыжок), который вызывал именно эти проблемы, о которых читатель этой книги теперь уже знает и может их предупредить.
Внедрение функции LEAP также требует наличия другой функции — функции LEAP AGAIN (Прыгнуть еще раз), с помощью которой выполняется переход к следующему экземпляру того же шаблона в том же направлении, в котором функция LEAP была применена последний раз. В компьютерах SwyftWare и Canon Cat поиск обычно осуществлялся в виде перехода (LEAP) к шаблону и затем использования несколько раз клавиши <LEAP AGAIN> до тех пор, пока не обнаруживался искомый экземпляр.
Функция LEAP позволяет унифицировать выполнение поиска и перемещения курсора внутри текста с учетом того, что текст может включать таблицы, графические элементы и любые другие алфавитно-цифровые символы. После некоторого периода использования функции LEAP пользователь перестает замечать процесс перехода (LEAPing) так же, как оператор, владеющий десятипальцевым методом набора, не замечает механического движения пальцев и концентрируется только на создании содержания. Если вы хотите разместить какой-то целевой объект на дисплее, вы «перескакиваете» (LEAP) к нему, и вам не нужно для этого останавливаться, чтобы найти этот объект внутри содержания системы. Вам не нужно проходить по иерархическим структурам или открывать папки. Вы просто «перепрыгиваете» прямо к тому, что вам нужно. Однако когда люди, привыкшие к стандартным файловым структурам, впервые сталкиваются с системой, снабженной функцией LEAP, они часто продолжают думать с точки зрения того, где нужный объект располагается иерархически, и поэтому ищут его, пытаясь установить его общее местонахождение, и затем перемещаются к искомому экземпляру по определенному пути. Если среда, внутри которой вы осуществляете поиск, хорошо индексирована, для пользователя становится не важным, находится ли искомый элемент в памяти, в локальном или сетевом хранилище или же в локальной или глобальной сети.
Говоря о методах поиска, следует упомянуть наблюдения, которые были сделаны Ландауэром (Landauer) и его коллегами. Ими было показано, что наиболее распространенные формы расширенного текстового поиска, в котором поиск определяется булевыми комбинациями строк или регулярными выражениями, менее эффективны в сравнении с полнотекстовым механизмом поиска. Последний оказывается и более быстрым, и более простым, и с помощью него пользователи находят больше подходящих элементов, по которым они производят поиск (Landauer, 1995). Как показывает GOMS-анализ и другие измерения эффективности, LEAP имеет преимущества над методами поиска, использованными Ландауэром, и поэтому обладает еще большей ценностью.
С каждой новой версией ваша любимая программа выполняет данную задачу в два раза дольше.
Линкольн Спектор
Современная структура программного обеспечения, состоящая из операционной системы и выполняемых под ней приложений, изначально является модальной. Это означает, что для того, чтобы интерфейс был немодальным, требуется подход, при котором не используются приложения в их современном виде.
Поскольку жесты (например, те, с помощью которых вызываются команды) из одного приложения не могут быть доступными в другом приложении, вы должны знать о том, какое приложение в данный момент является активным. Но вы не можете знать это наверняка, когда в локусе вашего внимания находится задача, которую вы пытаетесь выполнить. Поэтому иногда вы будете применять жесты, которые либо не будут давать результата, либо будут давать неправильный результат. Отдельной, создаваемой прикладными программами, стоит проблема, что средства одного приложения являются недоступными, когда вы находитесь в другом приложении. Например, ситуация может быть такой: вы хотите выполнить некоторую задачу, которую могли бы выполнить в приложении A. Но вы находитесь в приложении B, в котором аналогичной команды нет. Специалист по вычислительной технике Дан Свайнхарт (Dan Swinehart) назвал такую ситуацию «дилеммой вытеснения» (dilemma of preemption) (Tesler, 1981, с. 90).
Известны три подхода к решению дилеммы вытеснения. Наиболее распространенный метод заключается в том, чтобы каждое приложение снабдить всеми средствами, которые пользователю могут понадобиться. Этот метод обсуждался в разделе 5.1, где было указано, что в каждом персональном компьютере имеется множество различных текстовых редакторов. Большинство текстовых процессоров содержит в себе множество разных текстовых редакторов. Например, типичный текстовый процессор имеет более простой текстовый редактор для ввода шаблона в диалоговое окно поиска, чем тот, который используется для работы с основным текстом. При таком подходе приложения расширяются до колоссальных размеров, поскольку каждое их них должно решать огромное множество задач, которые имеют второстепенное значение с точки зрения его основной задачи. Например, мой текстовый процессор имеет встроенную программу для рисования, с помощью которой я могу создавать простые рисунки, без необходимости выходить из редактора. В то же время, моя программа для рисования графики имеет встроенный текстовый редактор, с помощью которого я могу включать в рисунки форматированные блоки текста без необходимости выходить из программы рисования. Средства рисования в текстовом редакторе и средства редактирования текстов в программе для рисования хуже, чем программы, которые разработаны специально для соответствующих задач. В идеале все команды и возможности как программы для рисования, так и текстового редактора должны быть доступными для пользователя в любой момент.
Аналогичным образом в каждой программе имеются средства для сохранения и открытия именованных файлов. Однако эти средства работают по-разному и имеют разные возможности в разных программах. Это приводит к путанице, трудностям в использовании и создает огромный объем избыточного программного обеспечения, которое требует оплаты, усилий на изучение, ведения документации, а также адекватного размера оперативной памяти и места на диске. То же самое касается и множества других возможностей (например, печати), которые дублируются (или очень похожи) в разных программах.
Эти проблемы в некоторой степени были учтены производителями и разработчиками. Ряд компаний разработали программное обеспечение, которое позволяет включать в единый составной документ (compound document) части, созданные в разных приложениях. Когда вы щелкаете мышью по любой точке в таком документе, автоматически активизируется приложение, в котором эта часть составного документа была создана. Этот метод позволяет избежать открытия явным образом соответствующих приложений при работе с составным документом. Конечно, для создания такого документа пользователю все равно приходится вручную запускать приложения, создавать части составного документа и затем собирать их в единое целое (обычно с помощью операций вырезания и вставки или перетаскивания).
Хотя этот метод и создает некоторое, самое небольшое удобство, дилемма вытеснения с помощью него не решается, что можно видеть на разных примерах (OpenDoc компании Apple, NextWave компании HP, OLE компании Microsoft и их производные). Когда вы работаете в одной из частей составного документа, у вас в распоряжении нет программных средств, которые используются для создания других частей. Более того, такой документ как бы не имеет границ, и его поведение неожиданным образом меняется в зависимости от места. Таблица и электронная таблица могут выглядеть одинаково, но одна действует по правилам текстового процессора, а другая — по правилам программы электронных таблиц. Это является злодейской модальностью, поскольку единственным признаком вашего местоположения является изменяющееся при щелчке меню, которое обычно расположено далеко от локуса внимания. Как мы уже знаем, это является неэффективным средством извещения пользователя о текущем состоянии системы. Хотя необходимо сказать, что абсолютного средства, конечно, здесь быть не может.
Оригинальным методом устранения режимов, которые присущи приложениям, было использование оконной парадигмы. Алан Кэй (Alan Кау) из компании Xerox PARC предложил перекрывающиеся окна (overlapping windows) для того, чтобы частично устранить модальность приложений. Он также хотел убрать разделение между операционной системой и приложениями, но успеха добился, главным образом, в том, чтобы сделать функционирование операционной системы видимым в форме так называемого рабочего стола. На то время это было действительно продвижением вперед, но, как выразился Ларри Теслер (Larry Tesler) из компании PARC, «окна, в некотором смысле, — это режимы в овечьей шкуре» (Tesler, 1981, с. 94). Это означает, что окна, по сути, не устраняют модальность приложений, но позволяют сделать видимыми и доступными одновременно множество приложений. Идея, предложенная Кэем, и другие идеи, возникшие на основе использования окон, стали важным шагом вперед, результатом которого люди пользуются более десяти лет. Однако проблема режимов и дилемма вытеснения, порожденная существованием приложений, так и не были решены. С того времени овечья шкура поизносилась, и из нее все чаще стал выглядывать на нас волчий зуб. В разделе 5.8 будет рассмотрен один из способов того, как можно окончательно разделаться с этим волком.
Калькулятор или компьютер?
Не секрет, что многие из нас держат рядом со своим компьютером калькулятор. Почему же нам требуется это примитивное устройство, когда в нашем распоряжении имеется целый компьютер? Причина в том, что для выполнения простых арифметических действий на компьютере нам приходится предпринять настолько изощренные манипуляции, что они могли бы быть достойны представления в цирке. Представим, что вы сидите за компьютером и набираете какой-то текст в текстовом процессоре и вам необходимо узнать, сколько стоит одна упаковка Phumuxx, при том, что 375 упаковок стоят $248.93. На моем компьютере мне приходится открывать окно калькулятора. Для этого я переношу руку с клавиатуры на мышь, с помощью которой выполняю команду выбрать и перетащить (click-and-drag), чтобы открыть окно калькулятора. Затем я переношу руки обратно на клавиатуру и ввожу нужные цифры или же долго сначала вырезаю их из текста, а потом вставляю в поле калькулятора. Потом мне нужно нажать еще пару клавиш и, наконец, скопировать полученный результат из окна калькулятора в документ. Иногда дело осложняется тем, что окно калькулятора открывается прямо поверх того места, где находятся необходимые мне числа. В этом случае я должен также использовать мышь, чтобы переместить окно калькулятора в другое место и продолжить операцию. Проще достать карманный калькулятор и с помощью него сделать все намного быстрее.
Более удачным решением было бы использование специальной кнопки Вычислить (Calculate) или сквозной команды меню, с помощью которой можно было бы вычислить выделенное арифметическое выражение (такое, например, как 248.93/375) в любой среде, будь это текстовый процессор, программа коммуникации или рисования, презентационное приложение или просто рабочий стол. Другими словами, это пример универсальной функции, применимой в любом месте.
С помощью эксперимента, в котором участвовал опытный оператор компьютера (и владелец калькулятора), я смог определить, что общее время, которое понадобилось оператору, чтобы во время использования текстового процессора достать калькулятор, включить его, выполнить простую операцию сложения и переместить руки обратно на клавиатуру компьютера для продолжения работы, составило около 7 с. Затем я измерил время, которое понадобилось ему на использование встроенного калькулятора. При этом оператору было необходимо переместить курсор к меню в верхней части экрана, найти программу калькулятора, открыть ее, получить сумму и затем щелкнуть по окну текстового процессора, чтобы вернуться к своей работе. Это заняло около 16 с.
Тому же оператору было предложено выполнить арифметическую операцию в середине документа при использовании компьютера Canon Cat со встроенной клавишей <Вычислить> и возможностью выполнять арифметические операции внутри документа. Время составило 6 с (цифры вводились с помощью верхнего ряда клавиш). Таким образом, в этом случае не было выгоды во времени от использования внешнего калькулятора. Кроме того, в компьютере Canon Cat после вычисления результат оставался в документе на случай, если пользователю требовалось вставить туда результат. В то же время, этот результат оставался выделенным, поэтому пользователь при необходимости мог легко его удалить нажатием на клавишу <Delete>.
В системе должна быть доступной также и другая возможность: в любом месте, где пользователь может ввести цифры, он должен иметь возможность ввести арифметическое выражение и вычислить его. Такие команды, как
- проверить орфографию в текущей выборке;
- использовать текущую выборку как арифметическое выражение и вычислить его;
- передать текущую выборку по электронной почте;
- передать текущую выборку по факсу;
- перейти по данному URL;
- выполнить текущую выборку как программу, написанную на языке Java или любом другом языке,
должны быть доступными для пользователя в любой момент, что является абсолютно выполнимым с точки зрения разработки.
Хороший дизайн является более важным, чем вы думаете.
Рекс Хефтмэн
Когда сложность некоторого продукта или части программного обеспечения, или компьютерной системы превышает наши в ней потребности и создает трудности, это вполне оправданно вызывает в нас раздражение. Даже если нам требуется поработать с каким-то простым текстом, мы вынуждены разбираться в сотнях или, как в случае с Microsoft Office, даже тысячах команд и методов, которые нам не нужны. С другой стороны, если бы мы могли пользоваться этими командами по мере возникновения в них необходимости, это сняло бы ощущение избыточности и огромного когнитивного груза, даже если бы вся система стала от этого столь же сложной, каким являлось до этого само приложение.
Мечта о том, чтобы продукты были изначально действительно (а не внешне) просты и в то же время гибки, может быть достигнута на основе подхода, в котором система не должна быть сложнее, чем ваши потребности в данный момент, и при котором возможности системы можно наращивать постепенно. Чтобы понять, как это сделать, вспомним, что в разделе 5.1 было сказано о том, что почти все действия, выполняемые с помощью компьютера, включают содержание, которое вы вводите или получаете, и набор операций, которые вы применяете к этому содержанию. Также вспомним, что интерфейс для любой такой операции состоит из двух частей: выборе содержания и вызова операции. Например, в игре требуется убить монстра, или, выражаясь более прозаическим языком, выполнить операцию по изменению изображения монстра на изображение взрыва. Содержание выбирается с помощью курсора (курсор подводится к монстру), а операция вызывается с помощью клавиши на ГУВ. Между прочим, это довольно хороший интерфейс — быстрый и результативный.
Вызов команды для применения к выборке может дать три возможности:
В первом случае операция выполняется и содержание видоизменяется. Во втором случае содержание остается без изменения. В третьем случае для выполнения операции должен быть вызван другой процесс, с помощью которого выборка предварительно модифицируется.
Предположим, что вы выбираете часть фотографии, на которой изображен вид городской улицы, и пытаетесь применить к ней команду проверки орфографии. Вызов этой команды предполагает наличие некоторой последовательности символов (текста), но здесь обнаруживается фотография (растровое изображение). Одной из возможностей компьютера является возможность преобразовывать содержание из одного типа данных в другой39. В этом случае данные являются растровым изображением, а команда применима только к текстам, поэтому компьютер должен определить, имеется ли какой-нибудь трансформатор для преобразования растровых изображений в текст. Вообще такие трансформаторы существуют. Это так называемые программы для оптического распознавания символов (optical character recognition programs). Обычно программы для оптического распознавания знаков (OCR-программы) используются для конвертирования данных, полученных с помощью сканера, в текст, который можно редактировать. (Некоторые из цитат, которые приводятся в этой книге, были получены с помощью сканирования соответствующих статей и последующего использования OCR-программы для конвертирования полученного растрового изображения в текст.) Допустим, что в компьютере имеется такая программа. Тогда эта программа автоматически запускается и анализирует растровое изображение. Если программа обнаруживает какие-то распознаваемые символы (например, знак остановки и частично читаемый знак с надписью «Первая северная уица»), то начинается проверка орфографии этих текстов, в результате которой выдается сообщение о том, что обнаружено неизвестное слово «уица», и предлагаются возможные варианты исправления: «улица», «утица», «ушица», «лица».
Программное обеспечение вместо того, чтобы состоять из операционной системы и набора приложений, рассматривается человекоориентированным интерфейсом как набор команд, некоторые из которых являются трансформаторами, автоматически вызываемыми в тех случаях, когда тип данных, предусмотренных командой, не соответствует типу данных выбранного объекта. При этом может быть вызвано более одного трансформатора. Предположим, что с помощью одного трансформатора производится конвертация из А в В, а с помощью другого — из B в С. Если команда предусматривает обработку данных типа С, а данные выборки представляют собой тип А, то перед выполнением команды должны быть запущены два трансформатора. Если необходимых трансформаторов не имеется, никаких изменений с выборкой не производится. Пользователю при необходимости выдается специальное сообщение, а выборка остается без изменений.
При таком подходе вместо прикладных программ разработчики будут поставлять наборы команд, представляющие собой совокупность взаимосвязанных операций. Например, вместо программы для обработки фотоизображений разработчик будет предлагать ряд отдельных команд, которые в совокупности будут давать те же возможности, что и программа. Пользователь сможет устанавливать столько команд, сколько ему необходимо, вместо того, чтобы устанавливать целое приложение, из которого ему может понадобиться только некоторая часть. С помощью Интернета передовой разработчик сможет продавать свое программное обеспечение отдельными командами и даже предусмотреть скидки на покупку определенных наборов или определенного числа команд.
Когда пользователи сетуют на невероятную сложность приложений и просят, чтобы программы были проще, «без этих ненужных колокольчиков и свистков», разработчики отвечают, что облегченные («lite») версии программного обеспечения зачастую не имеют успеха на рынке. Неудачи с облегченными версиями программных пакетов могут быть объяснены следующим образом. Поскольку пользователь никогда не знает, какие именно возможности полного пакета могут ему понадобиться, он покупает весь пакет, т.к. это единственный способ получения этих возможностей. Если пользователь приобретет ограниченную версию по меньшей цене, единственный способ, каким он сможет обновить эту версию, — это купить полный пакет, даже если пользователь хочет получить только какую-то одну небольшую функцию из этой программы. Поэтому выходит, что лучше сразу покупать полную версию и примириться с ее сложностью. В результате не удивительно, что мы оказываемся как бы в ловушке. Более гуманным подходом было бы предоставление возможности покупать команды по отдельности.
В различных обзорах сообщается о большом количестве никогда не используемых элементов того или иного программного обеспечения. В последнее десятилетие это число возросло приблизительно с 15% до почти 50%. Это создает большой беспорядок. Если же вместо приложений использовать наборы команд, каждая из которых может быть установлена независимо от других, пользователи сведут показатели этой статистики почти до 0. Другими преимуществами такого подхода для разработчиков является возможность поступенчато улучшать свои продукты, а также более простым образом и чаще поставлять (т.е. продавать!) новые элементы приложений, поскольку в этом случае производителям не придется каждый раз выпускать весь пакет заново. Интернет является самым подходящим средством для осуществления таких многократных поштучных продаж.
Разработчики (необязательно те же, кто выпускает наборы прикладных команд) также могут производить трансформаторы. И они тоже могут продаваться поштучно. Если большинство пользователей регулярно использует большинство команд текстовой обработки, выпущенных разработчиком А, и разработчик В придумает какую-то полезную команду, которую разработчик А не поставляет, то разработчик В сможет продавать эту команду покупателям продукта, производимого разработчиком А. Однако разработчик В может использовать другую структуру данных. В этом случае он может предложить также и трансформатор для перевода из одной структуры данных в другую, и наоборот. Если продуктом, производимым разработчиком А, пользуется большое число потребителей, разработчик В может создать версию данной команды, работающую непосредственно со структурой данных, предусмотренной разработчиком А. Кроме того, третий разработчик (С) может специализироваться на разработке трансформаторов. Для пользователей может стать обычной практикой покупать трансформаторы именно у таких разработчиков, а для разработчиков команд — давать лицензии на соответствующие трансформаторы. Эта коммерческая структура частично уже существует сегодня, и различные компании (например, DataViz) специализируются на разработке трансформаторов.
Элементы такой компьютерной среды «команды плюс трансформаторы» также существуют, и их нетрудно будет собрать в единую рабочую систему. Для пользователей такие системы будут проще в использовании и более гибкими в сравнении с сегодняшними разработками, ограниченными применением приложений. Такое решение может уменьшить степень избыточности и сложности, снять проблему совместимости между приложениями и необходимость многократно решать одну и ту же проблему. Со временем операционная система может полностью исчезнуть из поля зрения пользователя. Если этого подхода будут придерживаться должным образом, то даже общепринятая версия операционной системы — рабочий стол — не сохранится в ее сегодняшнем виде.
Конечно, не все программы должны быть построены по описанному принципу. Игры, например, должны просто запускаться и работать самостоятельно. Запуск должен осуществляться обычным путем — с помощью выбора (мышью или другим способом) имени игры (возможно, из текста, включающего список имен игр) и затем использования команды Выполнить (Execute). В разделе 6.2 также будет описан альтернативный метод.
Учтивое программирование: приложения как гости
Представим, что вы были приглашены погостить в доме ваших хороших друзей Гримблсов. И даже их собака кажется вам очень милой. Единственная проблема — это портрет их любимой тетушки Астабьюлы, который висит над вашей кроватью. Этот портрет вызывает у вас и вашей жены нервную дрожь, и вы не можете даже спать в комнате, в которой на вас смотрит с портрета тетушка Астабьюла. Вы не решаетесь сказать обо всем этом Гримблсам. Как бы вы поступили в такой ситуации, будучи гостем в доме своих друзей?
- Сняли бы картину и сожгли ее.
- Спрятали бы ее в винном погребе, чтобы Гримблсы после месяца поисков обнаружили ее там.
- Поставили бы ее в шкаф, чтобы Гримблсы нашли ее немного раньше.
- Поставили бы картину в шкаф и потом, перед отъездом, вернули бы ее на свое место.
Любой учтивый гость знает, что вариант 4 является самым правильным. Принцип заключается в следующем: если ты делаешь по тем или иным причинам изменения в чьей-либо среде, позаботься о том, чтобы поставить все вещи на свои места до того, как вернется хозяин.
Современные компьютеры имеют множество параметров изменения рабочей среды, в том числе громкость динамиков, разрешение экрана и глубину изображения, вид меню, шрифт по умолчанию. В компьютере Macintosh имеются сотни настроек, а в IBM-совместимых компьютерах, работающих с операционной системой Windows и пакетом Microsoft Office, это число превышает тысячу. В чем жздесь параллель с визитом к Гримблсам? Если вы используете чью-либо машину и изменяете в ней какие-либо настройки, то перед уходом вы, как человек учтивый, должны вернуть все изменения обратно.
Многие программы для нормальной работы требуют определенного разрешения экрана, определенного числа бит на пиксел или какой-то другой настройки параметров. Если же параметры настроены в системе неправильно, поведение программы может варьироваться в диапазоне от благовоспитанного до грубоватого или даже варварского. Ниже приводятся реакции различных протестированных мной программ в случаях, когда параметры монитора не соответствовали требуемым:
Полный отказ системы, после которого приходилось вручную производить перезагрузку компьютера.
Полный отказ системы с выдачей непонятного числового сообщения, после чего приходится нажимать на кнопку Перезапуск, чтобы произвести перезагрузку компьютера.
Выдается сообщение об ошибке, в котором говорится о необходимости настроить параметры экрана. Когда вы нажимаете на кнопку OK, это приводит к полному отказу системы.
Выдается сообщение об ошибке, в котором говорится о необходимости настроить параметры экрана. После нажатия на кнопку OK вы можете открыть панель управления и выполнить необходимые настройки.
Выдается запрос о том, нужно ли выполнить изменение параметров экрана. Если вы нажимаете на кнопку OK, настройки автоматически изменяются. Если вы нажимаете на кнопку Отмена, запуск программы прекращается, а параметры экрана остаются без изменения.
Параметры экрана изменяются без всякого предупреждения, и программа запускается.
В специальном диалоговом окне выдается сообщение о том, что можно изменить настройки экрана. Если вы нажимаете на кнопку OK, настройки изменяются, и программа запускается. После завершения работы программы настройки автоматически возвращаются в начальное положение.
Читатель из будущего может подумать, что полный отказ системы — это уж слишком. Ни один из вышеприведенных вариантов нельзя назвать достойным вежливого гостя, хотя вариант —7 приближается к тому.
Наилучшим вариантом является сочетание, включающее запрос, упомянутый в пункте —5, и способ выхода из программы, описанный в пункте —7. В маловероятном случае того, что изменение настроек экрана может помешать прохождению другого, параллельного или фонового процесса, такой запрос позволит отказаться от запуска программы.
Параметры экрана изменяются без всякого предупреждения, и программа запускается. По завершении работы программы настройки устанавливаются в начальное положение.
Другими словами, при запуске программы она будет просто выполняться предусмотренным образом, не влияя на работу других программ. Это может служить определением благовоспитанной компьютерной системы. Но что произойдет, если две программы, требующие разных экранных настроек, одновременно будут выдавать какие-то изображения? Вероятно, это будет ситуация, когда лошадь будет отображаться с одной цветовой палитрой, а рыба с другим разрешением.
Вариант из пункта 7, который распространен и может показаться приемлемым, является неудачным, поскольку в нем выдается «диалоговое» окно, которое, по сути, не дает никакого диалога. Это просто злоупотребление, потому что на сообщенную информацию пользователь не может дать качественный ответ, что только приводит к пустой трате времени. (Метод прозрачных сообщений, описанный в разделе 5.2.3, позволяет решить эту проблему.)
Прикладные программы, по сути, являются бременем для пользователя, но раз уж нам приходится работать с ними, давайте сделаем так, чтобы они работали как следует (см. также Raskin, 1993). Обобщая сказанное, повторим, что программа, или в будущем команда, должна автоматически выполнять перенастройку параметров, если это необходимо для ее нормальной работы. После завершения работы программы (или прерывания пользователем) все параметры должны быть восстановлены в исходное положение. Если восстановление невозможно или может привести к нежелательным побочным последствиям, должно выдаваться специальное предупреждение, в котором сообщалось бы об этих последствиях и предлагалось бы пользователю решить: продолжить ли действие или нет.
В настоящее время мы не можем применять к одному экрану разные режимы разрешения одновременно. Но это уже проблема другого рода. Тем не менее, на мой взгляд, пользователи были бы довольны, если бы работа каждого интерфейса руководствовалась пунктом 8.
27 Конечно, если в вашей операционной системе недопустимы длинные имена, то здесь появляется еще одна проблема.
28 Левый символ обычно удаляется командой Backspace. — Примеч. науч. ред.
29 Совсем недавно мне случилось попользоваться текстовым процессором с таким ограничением на размер абзаца. Я превысил это ограничение уже как только вставил в абзац фотографию. Когда я сказал об этом разработчикам, они признали, что никогда не думали об этом. Таким образом, никогда не следует ставить ограничения только потому, что так писать программу легче. Такие ограничения всегда будут слишком узкими.
30 Все это касается современных систем. В будущих, человекоориентированных системах пользователю никогда не придется явным образом делать сохранение информации.
31 Доктор Джеймс Уинтер (James Winter) из Information Appliance продолжил такого рода унификацию структуры, указав на то, что в английском языке уже имеется аналогичная иерархическая структура с символами-разделителям, которая используется для отражения высших уровней организации текста.
32 То же самое касается и файловых имен и меню, которые были предложены в этой книге.
33 Здесь я использую термин последовательность в математическом смысле, чтобы обозначить множество объектов, включающее первый объект, второй и т.д.
34 Поиск может быть либо с приращением (пошаговый (incremental) поиск), либо с убавлением (excremental).
35 Аналогичной проблемой является использование зарезервированных слов в языках программирования.
36 Наверное, когда-то будет создан музей форм взаимодействия, аналогичный музеям старого программного и аппаратного оборудования. Такой музей мог бы быть создан в Интернете.
37 Для того чтобы среднее время ответа не превысило 250 мс, можно использовать такие методы, как предпросмотр и индексирование.
38 Этот пример еще раз показывает, насколько важно проводить тестирование интерфейсов с помощью аудитории, на которую продукт ориентирован.
39 Этот класс функций иногда называется фильтрами. Однако термин фильтр подразумевает скорее отбор, чем преобразование. Поэтому я предпочитаю термин трансформатор, который редко используется в науке о компьютерах (и часто используется в описаниях схем), тогда как термин фильтр используется гораздо чаще (как, например, в выражении программа цифровой фильтрации (digital filter program)).
| <= Previous | Index | Next => |